Onetable
Description
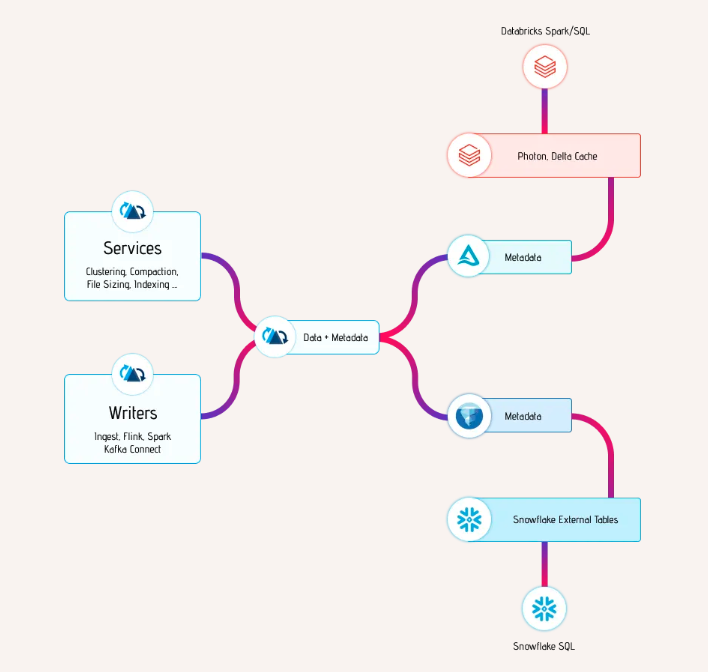
Onetable is powered by the open source Apache XTable project, which enables users to write their Onehouse tables in additional table formats including Apache Iceberg and Delta Lake. For example, users can add a Onetable catalog with Iceberg enabled to a Flow in order to query the destination Onehouse table as an Iceberg table. This is a common use case for users who want to use Iceberg or Delta Lake for their analytics or AI/ML workloads in platforms like Snowflake, Databricks, etc.
Table format syncs occur automatically when there is a commit to the Onehouse table. Onetable incrementally translates only the table metadata, not the data files, so any compute and storage impact is negligible.
Cloud Provider Support
- AWS: ✅ Supported
- GCP: ✅ Supported
- Azure: ✅ Supported
Example Architecture for Delta Lake (Databricks) and Iceberg (Snowflake) interoperability
Learn more about the Apache XTable project here.
Setup guide
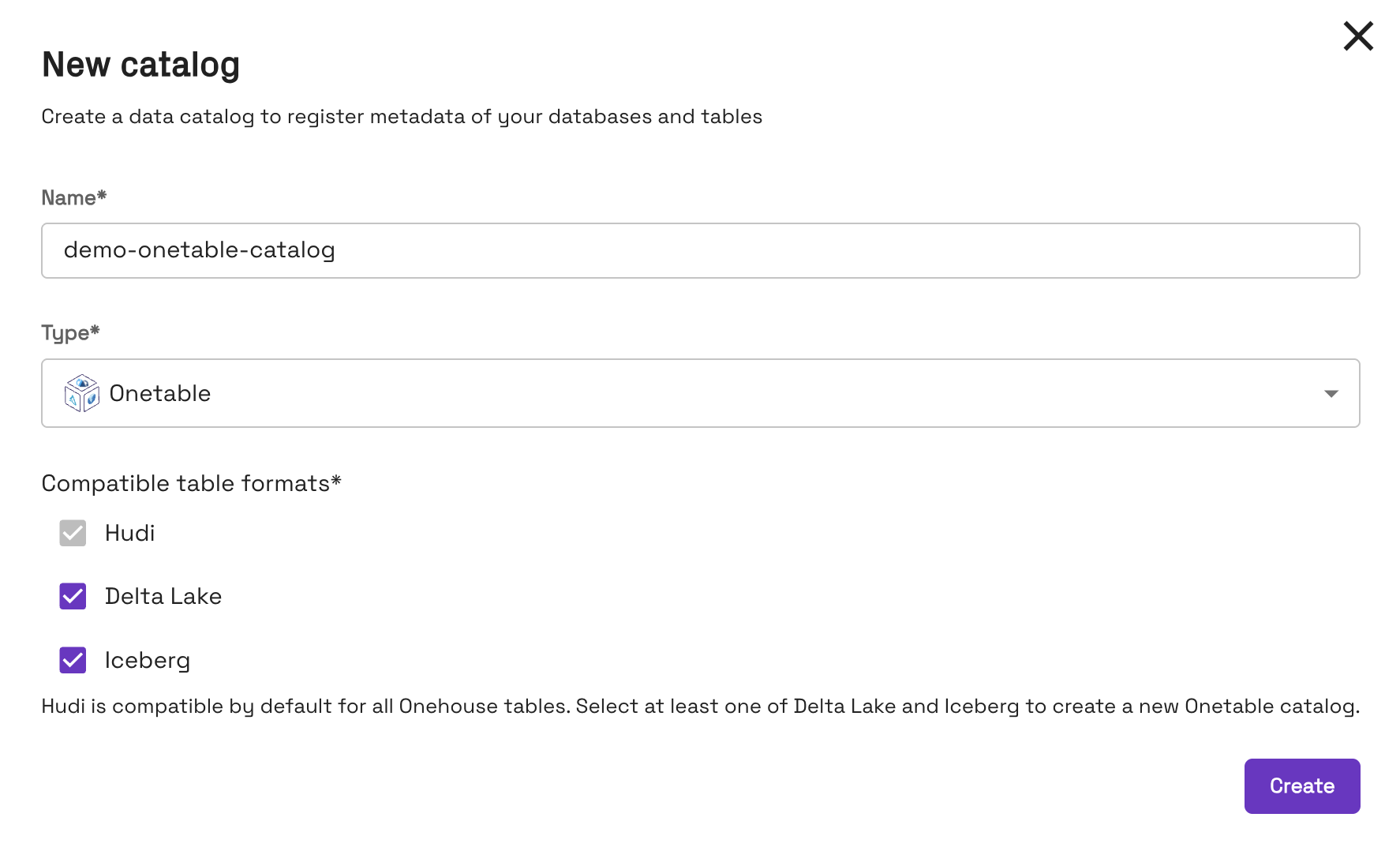
- Enter a name to identify the Onetable catalog in Onehouse
- Select "Onetable" as the Type
- Select compatible table formats. Apache Hudi is compatible by default for all Onehouse tables, so users should add at least one of Delta Lake and Apache Iceberg to create a Onetable catalog.
After creating the Onetable catalog, users will need to choose it for synchronization during the Flow creation process. This means that when Flow ingests data, Apache Iceberg and Delta Lake metadata files will appear in the S3 bucket alongside the Apache Hudi files.
Example Connection Setup for Onetable in Onehouse
Example Data in S3 Bucket