SQL
Create a Spark SQL Cluster to query tables and perform DML/DDL operations. Point tools such as dbt, Airflow, DbVisualizer at a Onehouse SQL Cluster to run queries on the Onehouse Quanton engine.
Architecture
Onehouse deploys a Spark Thrift server on AWS EC2 or Google Compute Engine instances within your VPC. Instances are pre-configured to run Spark SQL on Apache Hudi tables.
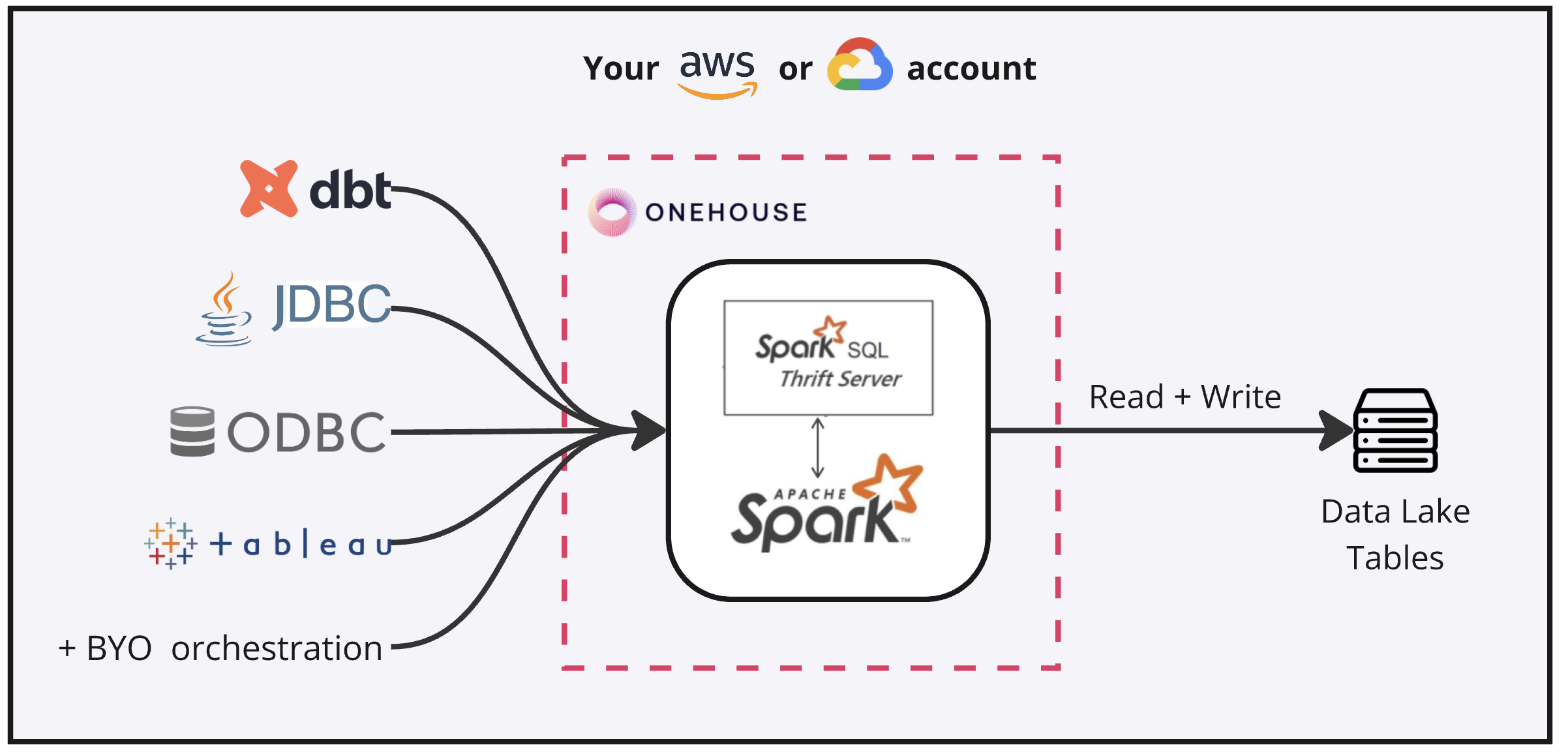
Connect to a SQL Cluster
Connect your tools directly to a SQL Cluster endpoint via JDBC. The instance runs Apache Spark, so you can connect via any Apache Spark integration (eg. dbt Spark adapter).
By default, SQL Clusters only accept requests from within the VPC. You can submit queries to a SQL Cluster endpoint from any tool within your VPC, such as beeline, dbt Core, Airflow, or DbVisualizer.
- Connect from within the VPC: Connect to the SQL Cluster locally through a VPN or set up a bastion host for tunneling into your VPC.
- Connect from outside the VPC: Contact Onehouse support if you need to point cloud tools outside the VPC (such as Preset or dbt Cloud) at a SQL Cluster.
Pre-Installed Libraries
- Apache Spark 3.5.2
- Apache Hudi 0.14.1
Billing
SQL Clusters are billed at the same OCU rate as other nodes in the product, as described in usage and billing.
Scaling & Max OCU
The SQL Cluster will scale up to the SQL Max OCU you set, and will scale down (to a 1 instance minumum) based on utilization.
Create a SQL Cluster
Prerequisite: Set Up a Lock Provider
Onehouse supports the following lock providers to ensure safe operations when a table has multiple writers:
- Apache Zookeeper
- Amazon DynamoDB
- Native S3/GCS based lock provider
This is a prerequisite for using Onehouse SQL Clusters.
Follow these steps to set up your lock provider:
- Create an Apache Zookeeper or DynamoDB lock provider.
- Apache Zookeeper: Create a Zookeeper that is accessible from your VPC.
- DynamoDB: Create a DynamoDB table in the same AWS account as your Onehouse project. Include an attribute with the name "key" and set this as the partition key of the DynamoDB table.
- In the Onehouse console, navigate to Settings > Integrations > Lock Provider. Add the lock provider you created in step 1.
- All Onehouse writers within the project will now use the lock provider you added. SQL Clusters can concurrently write to tables with other Onehouse writers such as Stream Captures and Table Services.
If you are using DynamoDB as your lock provider, Onehouse requires additional access. In your Onehouse Terraform script or CloudFormation template, ensure that enableDynamoDB is set to true.
Additional Tips on the Lock Provider & Concurrency:
- If you are writing to Onehouse tables with an external (non-Onehouse) writer, you should apply the same lock provider configs found on the table details page to avoid corrupting tables.
- When concurrent writers attempt to write to the same file group, one writer will fail gracefully (using Apache Hudi's Optimistic Concurrency Control). If you plan to write to the same file group with concurrent writers, it's useful to add failure retry logic in your orchestration and to consider temporarily pausing a writer if transactions repeatedly fail. Note that this only applies to transactions writing to the same file group.
- After a lock provider is added in the Onehouse console, you must contact Onehouse support to modify or remove it.
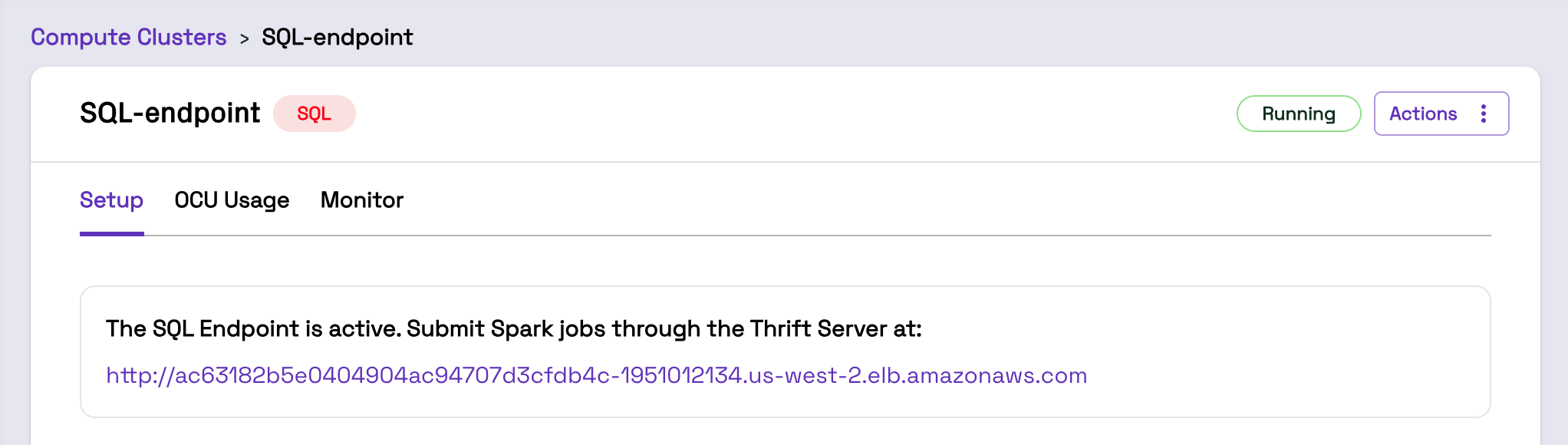
Create the SQL Cluster
Open the Clusters page and create a Cluster with type "SQL". After the Cluster is created and provisioned (which may take a few minutes), you will a SQL Cluster endpoint in the Onehouse console:
Write to Existing Onehouse Tables with SQL
Onehouse executes queries with Spark SQL, so all Spark SQL syntax is supported.
Important Usage Guidelines:
- DDL and DML Support: When writing to Onehouse tables, you can perform any of the SQL DDL and SQL DML commands described in the Hudi Spark SQL docs.
- Backwards Incompatible Evolution: Avoid performing schema evolution that is not backwards-compatible (e.g. adding a column with a non-null default value) via SQL on tables with active Stream Captures, as this may cause compatibility issues.
Create Onehouse Tables with SQL
When you create a table with SQL under the path of a Onehouse Lake, the table will automatically appear in the Onehouse console. You can view these tables on the Data page and configure table services. See the Examples section below for sample queries to create tables.
Important Usage Guidelines:
- Syncing to Catalogs: Use the MetaSync table service to sync tables created with SQL to any of your catalogs, such as Glue or Snowflake. Enable the MetaSync service via the Onehouse API (see examples section below) or set Default Catalogs for your project to automatically sync new tables created with SQL.
- Hudi Table Format: Create tables in the Apache Hudi format to ensure full compatibility with the Onehouse platform. Tables created in other formats such as Apache Iceberg will not be compatible with the metrics console and table services.
- Hudi Table Location: When creating Hudi tables with the a SQL Cluster, you may exclude the
LOCATIONparameter to create the table under the storage path of the table's database.
Sync Tables to External Catalogs
When you create a table with SQL, you may want to sync it to external catalogs such as Glue or Snowflake. You can enable the Metadata Sync table service in the Onehouse console or with the ALTER SERVICE IN TABLE API command.
You may also set one or more default catalogs to enable the Metadata Sync table service automatically for new tables in the project.
The Metadata Sync table service runs every ~15 mins to sync new tables and updates to your external catalog.
Write to Tables with External Writers
Onehouse SQL can also write to tables that have active writers outside of Onehouse (such as an external Spark platform).
When writing to tables concurrently with external writers and Onehouse SQL, you must follow these steps to ensure safe operations.
- Apply Lock Provider: Before writing to an external table with Onehouse SQL, you should stop all external writers and apply the same lock provider configs found on the table details page to avoid corrupting tables. Then you may resume external writers and write with Onehouse SQL concurrently.
- Set Configs in External Writer: To avoid data corruption, your external writer configs should match those of the Onehouse SQL writer. Set the following table configs in your external writer:
- Enable the Metadata Table with
hoodie.metadata.enable=true. - Enable timestamp ordering with
hoodie.timestamp.ordering.validate.enable=true. - Disable Hadoop with
parquet.avro.write-old-list-structure=false.
- Enable the Metadata Table with
- Avoid Writing in Multiple Table Formats: Data lakehouse tables must use a single table format for the writer (Apache Hudi, Apache Iceberg, or Delta Lake). Onehouse uses Onetable to translate tables into multiple table formats for readers, but all writers must use the same format.
- Refresh Outdated Cache: When writing concurrently with external writers, Spark cache may cause queries to fail or show an outdated state of the table. If this occurs, run
REFRESH TABLE <db>.<table>to get the latest table state. You can also avoid this by setting the Spark caching config:spark.sql.filesourceTableRelationCacheSize: "0".
Observability for SQL Queries
Monitor, optimize, and debug your SQL Queries with searchable driver logs and a Spark UI hosted within your VPC. In the Onehouse console under your SQL Cluster details, you will see a 'Monitor' tab with the following:
- Spark UI for Active Application: Link to the the Spark UI for the active Spark application running Spark SQL, hosted within your VPC. This includes SQL queries with status, duration, start/finish time, and logical plan.
- Spark UI for Past Spark Applications: Link to the the Spark UI for the historical Spark applications that ran Spark SQL, hosted within your VPC. This includes SQL queries with status, duration, start/finish time, and logical plan.
- Spark Driver Logs: Searchable logs from the driver running Spark SQL to help you debug issues.
The Spark UI is accessible from within your VPC. If you are using a bastion host, you may use a bash command like the following to port forward into your VPC:
ssh -L 8080:<sql-cluster-endpoint>:80 -N -f -i /my-credential.pem ec2-user@<bastion-host>
Then, in your browser, open the URLs provided from the Onehouse console for the Active and Historical Spark UI. If you are port forwarding, you should replace the load balancer URL with http://localhost:8000/.
Example Active UI Example URL:
http://localhost:8080/onehouse-sql/thrift-server-fu74hc59-e532-4d67-a3f8-83hrud7b9fdc/SQL/
Example Historical UI Example URL:
http://localhost:8080/onehouse-sql/thrift-server-pd920fht-08a1-407a-8194-38f136fc8e5b
For the Historical Spark UI, you can click into a specific Spark application, then click the SQL tab at the top to view the queries for that application.
Best Practices
- Check out the Apache Hudi docs on SQL DDL, SQL DML, and SQL Queries to learn about the SQL commands you can run on Onehouse tables.
- SQL Clusters query Onehouse tables directly as
table_name, without the_roand_rtviews (learn more).- By default, queries will be read-optimized (_ro), retrieving only compacted data. You can change to the real-time query type for the current session by running
SET hoodie.query.as.ro.table=false;.
- By default, queries will be read-optimized (_ro), retrieving only compacted data. You can change to the real-time query type for the current session by running
- You may set Spark properties with
SET <property>=<value>. These properties are persisted at the session-level, not globally for the Cluster. - You may set Hudi table properties with
ALTER TABLE tableIdentifier SET|UNSET TBLPROPERTIES (table_property = 'property_value');. These properties are persisted for the table, and will apply to any queries you run on the SQL Cluster. - Before performing operations that you may want to rollback (eg. deleting records), you can create a Savepoint in the Onehouse console on the table details page under the 'Operations' tab. Savepoints enable you to rollback the table to a previous point in time and re-ingest subsequent data from the source. For optimal performance, you should delete the Savepoint after it's no longer needed.
- If another writer evolves the schema while your SQL client (eg. beeline) is active, you might hit an error such as
UNRESOLVED_COLUMN.WITH_SUGGESTION. To get the latest schema, runREFRESH TABLE <db>.<table>or re-connect your SQL client.
Limitations
- SQL Clusters only supports Spark SQL. You cannot submit Spark code (eg. PySpark).
- Queries are automatically canceled after 24 hours of duration. Please contact support if you require longer-running queries.
- Java and Scala UDFs are supported, but Python UDFs are not yet supported.
- Similar to Stream Captures, SQL queries will fail if the data volume of shuffle operations exceeds the available storage (disk space) for the project. If you have use cases that require additional shuffle space (such as large joins or data explosion), you may increase the project's OCU Limit.
- Creating or dropping a database via SQL is not supported. You can do this via the Onehouse console.
- You need to set TBLPROPERTIES in order to run DML or DDL queries on certain Onehouse managed tables:
- If the table has a partition key, run
ALTER TABLE <table> SET TBLPROPERTIES (hoodie.datasource.write.partitionpath.field = '<partition_field>:simple').
- If the table has a partition key, run
- Using SQL to modify the name of a table created by a Stream Capture is not supported.
- Dropping a table from SQL will only drop the catalog entry for the table. You must delete the table in the bucket directly to remove the files.
- Tables created via SQL do not support default values. If you add new columns with
ALTER TABLE, any default value specified will be overridden tonull. We plan to resolve this limitation soon. - There is an issue may show incorrect metrics in the Onehouse console when
INSERT OVERWRITEis performed on a table. - When there are concurrent DDL requests (ALTER TABLE) to a SQL Cluster, one request may be dropped. For example, if you run
ALTER TABLE <db>.<table> SET TBLPROPERTEIS ('<key>' = '<value>'), double check that the TBLPROPERTIES key is set properly before executing subsequent commands for safety. - Changing a primary key value for an existing record in the table is not supported. Instead, delete the record and insert a new record.
- Changing a partition key value for an existing record is not possible with the
UPDATEcommand. Instead, useINSERT(in upsert mode) orMERGE INTO.