Clusters
Clusters allow you to isolate your workloads and independently scale compute resources. Each workload in Onehouse must be assigned to a Cluster.
Cluster types
Each Cluster has a specific type that determines the types of workloads you can run on the Cluster. A Cluster's type cannot be changed after creation.
Cluster types:
- Managed: Run Stream Captures and Table Services.
- SQL: Submit Spark SQL queries through the SQL Endpoint or SQL Editor. Each SQL Cluster has its own endpoint url for submitting queries.
- Spark: Create and run Jobs to execute Spark code.
- Open Engines: Deploy open source compute engines on Onehouse infrastructure with Open Engines.
You can always move workloads between different Clusters of a compatible type.
Additionally, each Onehouse project comes with the following view-only Clusters, which cannot be modified, deleted, or assigned workloads:
- System (view-only): Runs essential operational tasks such as monitoring, job scheduling, autoscaling, and other tasks to ensure the continuous operation of your pipelines. This is enabled for all Onehouse projects, and cannot be disabled. The consumption of this Cluster may grow if the scale of your project requires additional overhead to ensure smooth operations.
- Connector (view-only): Runs all resources required for source connectors, such as event notification consumers for file sources and change data capture (CDC) event listeners for database sources. If a project has no file or database CDC sources, it will not run a Connector Cluster.
The System and Connector Clusters do contribute toward a project's OCU consumption.
Create a Cluster
Visit the Clusters page in the Onehouse console to create a new Cluster. Below we will cover the configurations to set up the Cluster.
You may create multiple Clusters of the same type to isolate different workloads.
Basic configurations
- Name: The name by which to identify the Cluster.
- Cluster Type: The type of Cluster, as explained above. This cannot be changed after creation.
OCU configurations
Specify OCU limits to constrain the min/max Onehouse Compute Units (OCU) the Cluster will use per hour. This will determine the how many instances the Cluster can use, based on the hourly OCU cost of your selected instance type(s).
- Max OCU / Hour: Maximum OCU the Cluster will use per hour. Set this to manage your costs.
- Min OCU / Hour: Minimum OCU the Cluster will use per hour. Set this higher if you need to keep the Cluster warm.
Setting Max OCU for your Clusters can help you confidently keep costs under a budget. If your data volumes or complexity of the workload change and your Cluster usage hits its Max OCU, the Cluster will not continue scaling up. This may lead to delays in data processing, so it is important to consider how your workloads grow or fluctuate.
Instance type configurations
Specify the instance types for the Cluster. Learn more about the available instance types, custom instance types, and OCU costs here.
- Worker Type: Specify the instance type for the Cluster's workers (aka executors).
- Spot Instances: Optionally enable spot instances for the Cluster's workers.
- Not enabled by default.
- Enabling this may help reduce your cloud provider compute costs for workloads that do not require high-availability.
- Enabling this will not affect OCU pricing.
- This configuration only enables spot instances for workers. Drivers will always use on-demand instances.
- Driver Type: Specify the instance type for the Cluster's driver(s).
- When set to
Auto(the default option), drivers will use the same instance type as workers.
- When set to
Cluster usage notifications
You may set an OCU Limit Notification Threshold to receive a notification when the Cluster has scaled to X% of the Maximum OCU. Usage is calculated as the average over the past hour.
The default notification threshold is 80%, but you can set this to any value, or set 0% to disable notifications.
Notifications are received via the Onehouse UI, email, and (if configured) Slack.
Vectorized execution
Currently available for the SQL and Spark Cluster types.
Vectorized execution can provide performance gains on certain workloads. Currently, it performs best on workloads containing heavy scans and transformations (eg. reading data, joins, aggregations, etc.).
When an operation is not supported by vectorized execution, it will fallback to standard execution in most cases, but may fail in rare cases. We suggest starting with low priority workloads on a Cluster with vectorized execution enabled, then moving over more workloads.
Default Managed Cluster
Each new Onehouse project comes with a Default Managed Cluster. New Stream Captures and Table Services will be automatically assigned to this Cluster unless otherwise specified during their creation.
You can change the Default Managed Cluster anytime on the Settings > Project Settings page; changing this will not affect existing Stream Captures and Table Services. Note that you can only change this to another Managed Cluster with "Everyone can Use" permission.
Services Cluster
Each Onehouse table is assigned a Services Cluster to run its Table Services. To change a table's Services Cluster, navigate to the table on the Data page and use the Services Cluster dropdown to select a different Managed Cluster.
Default Services Cluser for new tables:
- New tables created by Stream Captures will use the Stream Capture's original Cluster as their Services Cluster.
- New tables created by SQL or Jobs will use the project's Default Managed Cluster as their Services Cluster.
Tables with an active Stream Capture will always use the Stream Capture's Cluster as their Services Cluster, for optimal performance. Changing the Cluster of a Stream Capture will also change the Services Cluster for the table.
Cluster permissions
Learn more about Cluster roles and permissions here.
Cluster resource sharing
Onehouse shares resources between Clusters to optimize resource consumption, enabling workloads from multiple Clusters to run on the same instances.
With Cluster resource sharing, strict Cluster-level isolation is maintained through control groups managed by Onehouse.
Cluster resource sharing helps reduce idle CPU, which occurs when resources are inefficiently allocated in a computing system, potentially causing suboptimal performance and underutilization. By bin-packing workloads from multiple clusters into the same shared instances, Onehouse reduces idle CPU and helps you achieve better performance at lower cost.
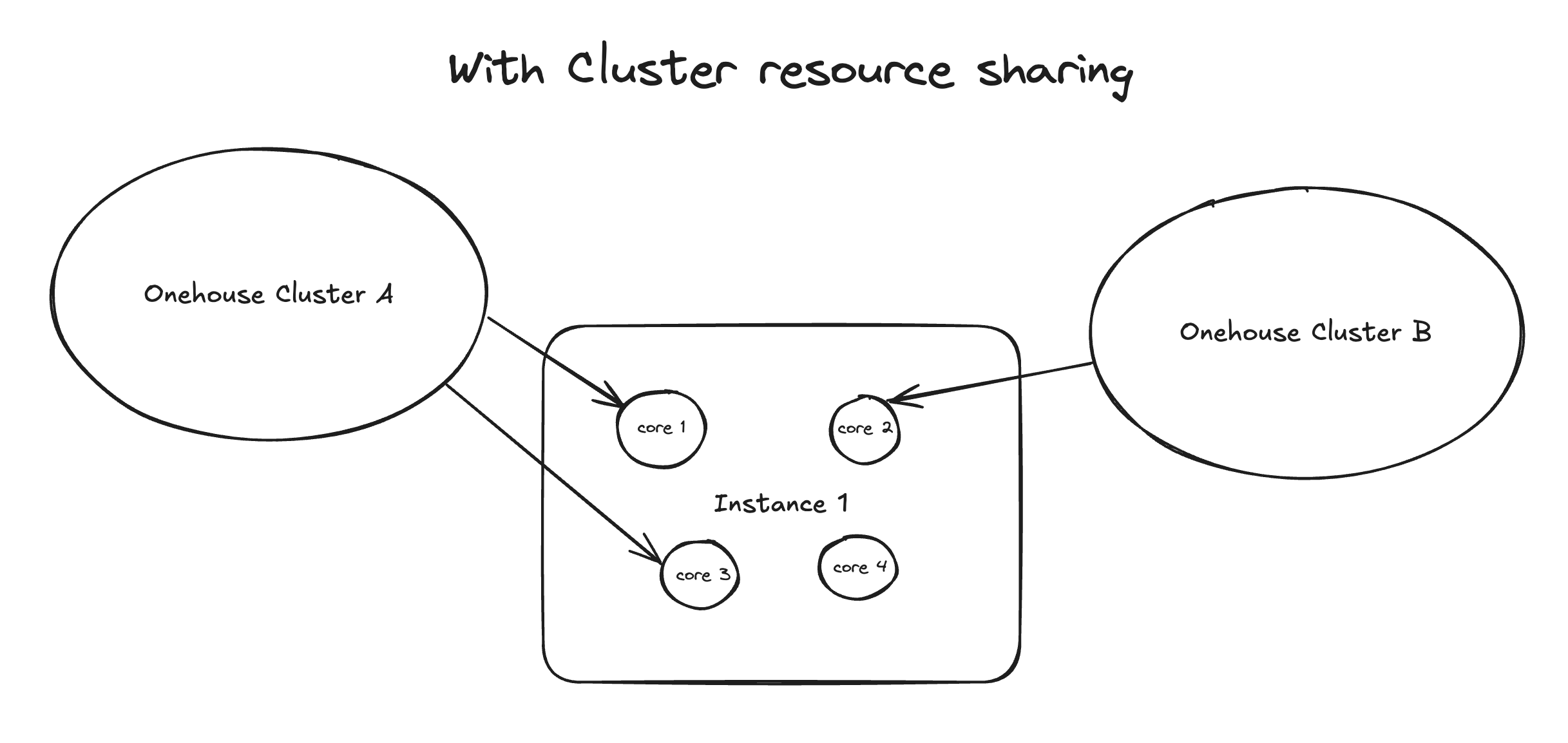
Example Scenario
To understand how Cluster sharing reduces idle CPU, we can look at a realistic example. Imagine you have 2 Onehouse Clusters, A and B. Cluster A is running a workload that requires 2 cores for processing, and Cluster B’s workload requires only 1 core. In this example, Onehouse is running on standard 4-core instances.
With Cluster sharing, both these workloads are bin-packed into a single instance, which is billed at 1 OCU per Hour. Without Cluster resource sharing, each Cluster would run on a separate instance, costing you 2 OCU per hour and leaving more CPU idle.
In both cases, there are some idle CPU, but Cluster resource sharing reduces the idle CPU and costs.
Impact on Billing
As explained above, Onehouse calculates OCU consumption for billing based on the number instances running in your account, not from any other utilization metrics.
The Onehouse console will show granular metrics for the CPU used by each Cluster, which may be split across multiple instances under the hood. The overall OCU consumption is calculated from the total instances used by your project, which may be greater than the sum of each Cluster’s OCU usage.
The difference in these values is due to idle CPU, which still exist, but are reduced by the Cluster resource sharing. The idle CPU may be caused by a variety of factors such as instance spin-down time during downscaling or un-allocated CPU on a Cluster if a workload cannot be perfectly bin-packed.
Best practices
- When possible, run workloads on the same Cluster to enable resource sharing (ie. multiplexing and bin-packing), which allows for more efficient OCU usage.
- You can get optimal performance by running Table Services and Stream Captures in the same Cluster for a given table. By default this will be the case for every new table unless you explicitly change the Services Cluster.
- A Cluster will restart when you edit the OCU or instance type configurations. In-progress queries and jobs on the Cluster will be canceled.
When to isolate resources into separate Clusters
- You have a small subset of high-priority Stream Captures ingesting data for business-critical dashboards. You want to ensure these high-priority Stream Captures do not lag when data volumes spike across the project, so you assign them to a separate Cluster with dedicated resources.
- You have latency-sensitive near-realtime data streaming into a table, and want to run a non-latency-sensitive backfill workload on the same table. You can use Clusters to keep the realtime stream on dedicated compute so the backfill workload does not cause lag for the latency-sensitive data.
- You have multiple teams sharing a Onehouse project and want to give each team dedicated OCU resources so teams cannot hog resources from each other.
- You want to provide dedicated OCU resources to "speed up" a certain workload, such as a large bootstrap from Kafka.