Stream Captures
Overview
Stream Captures capture data from a Source and write incrementally to a new Onehouse table. You may use Stream Captures to ingest data from external sources into Onehouse or to create derived tables from an existing Onehouse table.
Onehouse tables are always created as Apache Hudi Merge on Read tables. You may add Apache Iceberg and/or Delta Lake compatibility to your tables with the OneTable catalog.
In the Onehouse console, open the Capture page, then click Add New Stream. From here, you can create Stream Captures.
Step 1: Select a Data Source
Select an external data source or an existing Onehouse table (available if you've already ingested data into Onehouse). You may also add a new source by following the instructions in the docs.
Step 2: Configure your Stream Captures
Below are all the possible configurations. Depending on your data source, certain configurations will not be available. Note that Onehouse will only show the configurations available for the data source you've selected.
Write Mode
You may select between the following write modes:
- Mutable (Inserts, Updates, and Deletes): Stream Capture will append Inserts and merge Updates and Deletes into your table. Streams in the Mutable write mode also support syncing database changelogs from a database connector (e.g. Postgres, MySQL, MongoDB).
- Append-only (Inserts only): Stream Capture will append all records to your table. This avoids the overhead of looking up records to merge or delete.
Note that both write modes will create an Apache Hudi Merge on Read table.
Performance Profile
The Performance Profile allows you to optimize your Stream Capture for fastest read, fastest write, or a balance between the two. You can edit this configuration after creating the Stream Capture, so we suggest starting with the "Balanced" profile and later adjusting based on the Stream Capture's performance.
You may select from the following options for Performance Profile:
| Balanced | Fastest Read | Fastest Write | |
|---|---|---|---|
| When to Use | Use Balanced for a combination of fast write and read performance out of the box. | Use Fastest Read to get optimal query performance on the table with the initial write. Optimizations take place during writing, which will cause ingestion to take longer. | Use Fastest Write for high-throughput sources requiring rapid ingestion. You can then run clustering to optimize the read performance after the initial write. |
| Operation Performed | Bulk Insert | Insert | Bulk Insert |
| Sorting | Sorted by the partition path and Sorting Key Fields (or Record Key Fields if no Sorting Key) | No sorting by writer (coming soon). Use Clustering to sort. | No sorting by writer. Use Clustering to sort. |
| File Sizing | Enabled; Best Effort | Enabled; Guaranteed | Disabled |
Usage notes:
- Performance Profile is currently available for Stream Captures in Append-only write mode.
- "Fastest Write" is not suggested for high-cardinality updates where you are updating >100 partitions in a single input batch.
- Sorting is currently not available when using "Fastest Write" or "Fastest Read".
Sync Frequency
Configure how frequently to capture new data. A lower frequency will keep data up-to-date, but will be more costly.
Bootstrap Data
For file storage sources (e.g. S3 or GCS), you can choose to capture only new data or bootstrap the table with the existing data in the bucket.
- If you bootstrap data, the Stream Capture will bulk load existing files into the Onehouse table, then ingest new files.
- If you do not bootstrap data, the Stream Capture will skip all existing files and only ingest new files into the Onehouse table.
Source Data Location
For file storage sources (e.g. S3 or GCS), specify the location and format of the source data.
- Folder: Specify the parent folder to ingest your data from.
- File Path Pattern: Optionally specify a regex pattern filter for files in the source folder.
- File format: Select the file format of the data in your selected folder.
- File extension: Onehouse will automatically fill this in. If the data is compressed, change this to the compressed file extension (e.g. .zip).
Ingest from Multiple Sources
Ingest data from multiple Kafka clusters into one table. Add multiple Kafka sources to your stream, then input the details for your distributed lock client to coordinate concurrent writes to the table. Onehouse currently supports the following distributed lock clients:
- DynamoDB (AWS projects only): Provide your DynamoDB instance details and ensure you've granted Onehouse write permissions for DynamoDB.
- Coming soon: File-based clients
Select source Tables, Folders, or Topics
Depending on your Source type, you will select the source tables, folders, or topics for your Stream Capture. Onehouse will create a separate table for each source table/folder/topic you select.
For Kafka sources, you can enable Auto Capture to continuously monitor and capture new topics using filter conditions you define with regex. If you enable Auto Capture, you'll enter a Table Name Prefix that Onehouse will prepend to each topic name (joined by an underscore) to help you identify the tables captured by the stream.
Source Data Schema
Onehouse allows you to provide a source schema for your incoming data. When you provide a source schema, Onehouse will attempt to match incoming records to the provided schema.
For certain types of Sources, Onehouse can infer the schema from the source data, so you do not need to provide a source schema.
Onehouse also supports schema evolution when source data changes.
Pipeline Quarantine
When incoming records cause an error (e.g. schema mismatch) or fail to meet a Data Quality Validation during ingestion, you may either quarantine those records or fail the pipeline.
If Pipeline Quarantine is enabled, Onehouse will write invalid records to a separate quarantine table so your Stream Capture can continue uninterrupted. You may find the quarantine table storage path in the Table details page under Data.
If you choose to fail the pipeline upon invalid records, the pipeline will fail and stop running when an incoming record causes an error or fails to meet a Data Quality Validation.
Transformations
Add transformations to transform data during ingestion. Learn more about transformations in the docs.
Key Configurations
Record Key Fields
Onehouse uses the record key to identify a particular record for de-duplicating, updating, and deleting records. This is similar to a Primary Key in traditional databases.
The values in your record key field should be unique (e.g. UUID). Setting a record key field is required for mutable tables.
Partition Key Fields
You may partition data using partition key fields. Ensure the value type (and format if applicable) of your partition key field matches your data; otherwise, your stream will fail.
You may configure a setting to partition your Onehouse tables using Hive style.
ℹ️ Avoid creating too many partitions to ensure the Stream Capture runs efficiently. For example, if your partition is in the Timestamp format, set the output path format to Year, Month, or Day to write all records with the same Year, Month, or Day in the same partition.
Partition key fields play a critical role in query performance. Query performance will be optimal when partition columns are used as a predicate in the query.
Precombine Key Fields
For Mutable Write Mode
If your Stream Capture attempts to write multiple records with the same key value, Onehouse will only write the record with the largest value for the precombine key field you select. Setting a precombine key field is required for mutable tables.
Sorting Key Fields
For Append-only Write Mode
Set a sorting key to sort incoming records when they are ingested. This may speed up incremental queries of the table. Sorting by date also helps handle late arriving data.
Kafka Starting Offsets
For Kafka sources
Set the starting offset of Kafka source ingestion. With earliest, ingestion starts from the earliest Kafka offsets, and with latest, ingestion starts from the incoming data. This configuration cannot be modified after the stream has been created.
Advanced Configurations
Advanced configurations for Stream Captures can be entered through a text box in the Onehouse console or provided via the API (API reference here). These configurations are always optional.
To add advanced configurations while creating a Stream Capture in the Onehouse console, open the advanced configurations toggle and enter each configuration and value in single quotes as a comma-separated key-value pair. Example:
'streamCapture.configA' = 'true',
'streamCapture.configB' = '100'
Below are the available advanced configurations:
| Config Name | Default | Options | Description | Editable |
|---|---|---|---|---|
| streamCapture.delayThreshold.numSyncIntervals | 0 (off) | Any positive integer, or zero to disable the Delay Threshold. | This value is multiplied by the Sync Frequency to determine the delay threshold. When a sync's duration surpasses the delay threshold, the Stream Capture is considered delayed. | Yes |
| streamCapture.deduplicationPolicy | 'none' |
| Available for append-only Stream Captures only. Drop incoming duplicate records based on the record key. | Yes |
| streamCapture.kafka.missingMessages | 'FAIL' |
| Case-sensitive. For Kafka sources, controls Stream Capture behavior when encountering missing or expired messages. | Yes |
Multi-Table Select
If you have multiple tables under one S3 folder, Onehouse can capture them all at once. Provide a directory, then Onehouse will show all the sub-folders which you can choose to capture.
Step 3: Select Destination
Select Lake and Database
Your Stream Capture will write the generated tables to a database within a Onehouse data lake.
Select Catalogs
Onehouse will regularly sync the generated tables with your selected catalogs.
Stream Capture Actions
Clone
Cloning a Stream Capture will open the Stream Capture creation page with the same configurations pre-filled.
Pause
Pausing a Stream Capture will immediately stop processing data, and any in-progress sync will stop writing to the table. Pausing the Stream Capture will retain a checkpoint of the last processed data from the source, so you can later resume from the same position.
When a Stream Capture is paused, all optimizations running on the destination table will automatically be paused as well.
Resume
Resuming a paused Stream Capture will begin processing data from the last processed checkpoint in the source. The Stream Capture will fail if it attempts to process data that is no longer available in the source (for example, due to Kafka retention period).
Delete
Deleting a Stream Capture will remove the Stream Capture from your project. The Stream Capture will immediately stop processing data, and any in-progress sync will stop writing to the table.
The destination table will NOT be automatically deleted from storage or the Onehouse console. All optimizations running on the destination table will automatically be paused.
Clean & Restart
Performing a Clean & Restart on a Stream Capture will archive the destination table and restart processing from the earliest available data in the source.
To ensure you do not lose historical data or break downstream queries, Onehouse versions every table by storing the data within a subfolder in the format s3://<tablePath>/<tableName>/v<versionNumber>/. The Onehouse console displays the latest version for each table as DFS Path on the table details page. When you Clean & Restart a table, the Stream Capture creates a new version with an empty table and stops writing data to the current version. If the table is synced to catalog(s), you can continue querying the current table version while the Clean & Restart operation is in progress. As soon as the first commit is made to the new table version, Onehouse updates the catalog(s) to point to the new version so subsequent queries read the new version.
Editing Stream Captures
After creating a Stream Capture, you are able to edit the following configurations:
- Name
- Data Source
- Sync Frequency
- Pipeline Quarantine
- Transformations
- Data Quality Validations
- Catalogs
Editing the Data Source
You are able to edit the data source for any Stream Capture. Currently, the new data source must be a Kafka type.
When editing to a new Kafka source, you can choose the source topic, starting offsets, and source schema.
Note that if you Clean & Restart the Stream Capture after editing the source, the re-created Stream Capture will only capture data from its current source.
Syncs and Delays
Sync Process
Stream Captures process data incrementally through recurring syncs based on the specified minimum sync frequency. Each sync processes all the data available at the point of time of the trigger.
Each sync performs the following actions (in order):
- Stream Capture wakes up and checks if new data is available to process.
- Starts processing all new data that was available at the point of time of trigger.
- If a Source Data Schema is specified, that schema is applied all incoming records; records that do not match the schema are quarantined or fail the Stream Capture.
- Note: For S3 and GCS sources, incoming files that do not match the provided Source Data Schema will cause the Stream Capture to fail (not quarantine data). You may alternatively set the Stream Capture to infer the source data schema and quarantine invalid records by applying a data quality validation for the target schema.
- Applies all transformations to the incoming records.
- Applies all data quality validations to the transformed records. Records that do not match the validations are quarantined or fail the Stream Capture.
- Writes transformed records to the destination table.
- Syncs to catalog(s) and performs XTable metadata translation.
- Performs any table services scheduled for the sync.
- When complete, the Stream Capture waits until next trigger interval.
Example: Basic Sync

- Stream Capture triggers T1 at min0 and starts sync1 ingestion for all data it found available in Kafka at min0
- Stream Capture may make N number of commits to the table during the sync and will wait once complete until T2
- T2 at min5 and will start sync2 for all data that came into Kafka between min0-min5
Example: Sync with Insufficient Resources
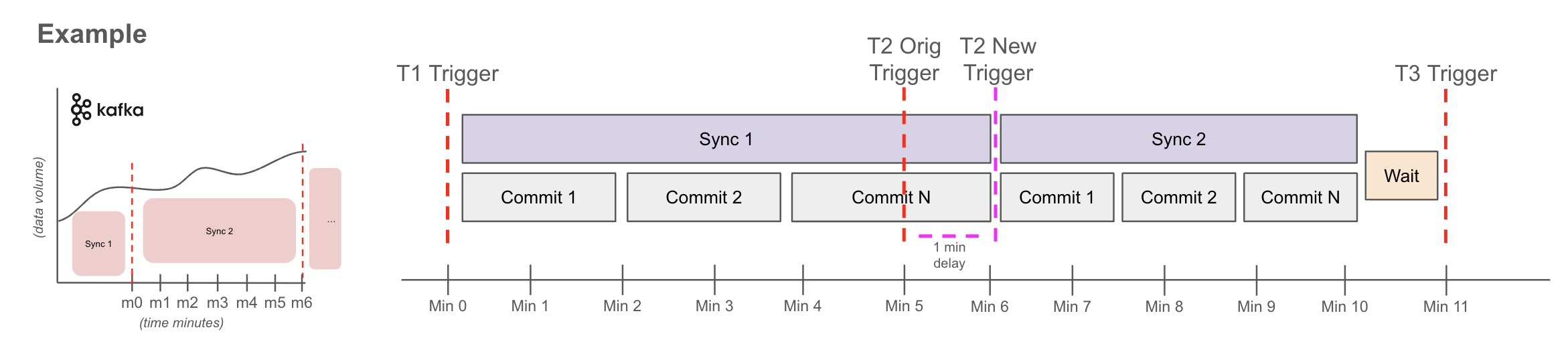
Sync1 - delayed
- T1 at min0 starts sync1 ingestion for all data it found available in Kafka at min0.
- Sync1 did not finish before T2, so T2 will now fire as soon as Sync1 is done. In this example it was 1min late completing at min6.
Sync2 - on time
- T2 at min6 starts sync2 ingestion for all data found available in Kafka at min6.
- If sync2 finishes before T3, it waits until the sync frequency time has elapsed before beginning sync3. In this case, this means the Stream capture successfully caught up to stable state.
Sync2 - Alternate scenario - delay
- If sync2 did not finish before T3, then T3 would trigger sync3 immediately after sync2 completes. This cycle would continue until the stream capture catches up.
Duration Definitions
- Sync Duration: Time it takes for the Stream Capture sync measured from start of trigger to completion (including transformations, catalog syncs, etc.).
- Commit Duration: When writing data, Onehouse breaks the data into commit batches. A single sync may write data in many commits.
How Syncs Optimize Resource Usage
- Compute resources for a Stream Capture are only allocated and used during the sync. During the period between syncs, the Stream Capture does not use any resources. Note that each Lake will keep one OCU active to check for new data.
- If the source has no new data to process at the start of the sync, the sync is skipped to preserve resources.
Delays
A Stream Capture is considered delayed when a sync takes longer than the delay threshold.
The delay threshold is disabled by default for new Stream Captures and can be set in the Stream Capture's advanced configurations. The delay theshold is calculated as streamCapture.delayThreshold.numSyncIntervals * Min Sync Frequency.
If the active sync surpasses the delay threshold, the Stream Capture will move to the Delayed status. The Delayed status is purely informational and will not change the functionality of the Stream Capture. The Stream Capture will move back to the Running status after another sync completes within the delay threshold.
When a Stream Capture is delayed, you will receive a notification (capped at 3 notifications per Stream Capture per day). You will also receive a notification when the Stream Capture returns to the Running status.
Suggestions for handling delayed Stream Captures:
- Review the minimum sync frequency. A lower minimum sync frequency (ie. more frequent syncs) will generally require more compute resources.
- Review the OCU Limit for the project. If your project is hitting the OCU limit, the Stream Capture may not have enough resources to process incoming data within the expected interval.
Onehouse also provides charts and metrics to help you understand Stream Capture delays. The Stream Capture details page exposes charts for the Sync Duration and Data Pending to Write (ie. data in the source that has not been processed). For additional granularity and customizability, Advanced Monitoring provides lag monitoring charts and metrics.
Statuses
Stream Captures can have the following statuses:
- Running: The Stream Capture is active. This state does not specify whether an active sync is in progress.
- Delayed: The Stream Capture's in-progress or most recent sync took longer than the specified delay threshold.
- Paused: The Stream Capture is paused and will not perform syncs.
- Failed: The Stream Capture encountered errors after three attempts to sync data. While in the failed state, the Stream Capture continues to retry on an interval that increases with each failure. If a sync succeeds during a retry, the Stream Capture moves to the Running status.
Usage Guidelines
- Stream Captures will fail if the data volume of shuffle operations exceeds the available storage (disk space) for the project. If you encounter situations that require additional storage (e.g. exploding an array with many elements), you may increase your OCU Limit or contact Support for additional guidance. Learn more about compute and storage resources that Onehouse provisions in your account in the AWS architecture and GCP architecture docs.