Create a Java or Scala (JAR) Job
JAR (Java archive) Jobs in Onehouse allow you to run an Apache Spark application in Java or Scala.
JAR Job Quickstart
Prerequisites
- Use JDK 1.17 for the best compatibility.
- Ensure you have the Project Admin role. This is currently a requirement for creating Jobs.
- A Cluster with the 'Spark' type to run the Jobs. You will need access to an existing Cluster in your project, or create one by following these steps:
- In the Onehouse console, navigate to the Clusters page.
- Click 'Add new Cluster'.
- Select 'Spark' as the Cluster type.
Step 1: Build and upload your JAR
Build and upload your JAR containing the executable and dependencies.
Download the demo Java application: 📎 SparkJava.zip.
- In your local environment, unzip SparkJava.zip, then navigate to the
SparkJavaparent directory. - Build a fat JAR with the Jackson JSON library included:
./gradlew shadowJar - The JAR will be created under the
SparkJava/build/libs/directory. - Upload the JAR to an object storage bucket accessible by Onehouse.
tip
Onehouse will always have access to the bucket named
onehouse-customer-bucket-<request_id_prefix>. You can retrieve the request ID for your project by clicking on the settings popup in the bottom left corner of the Onehouse console.
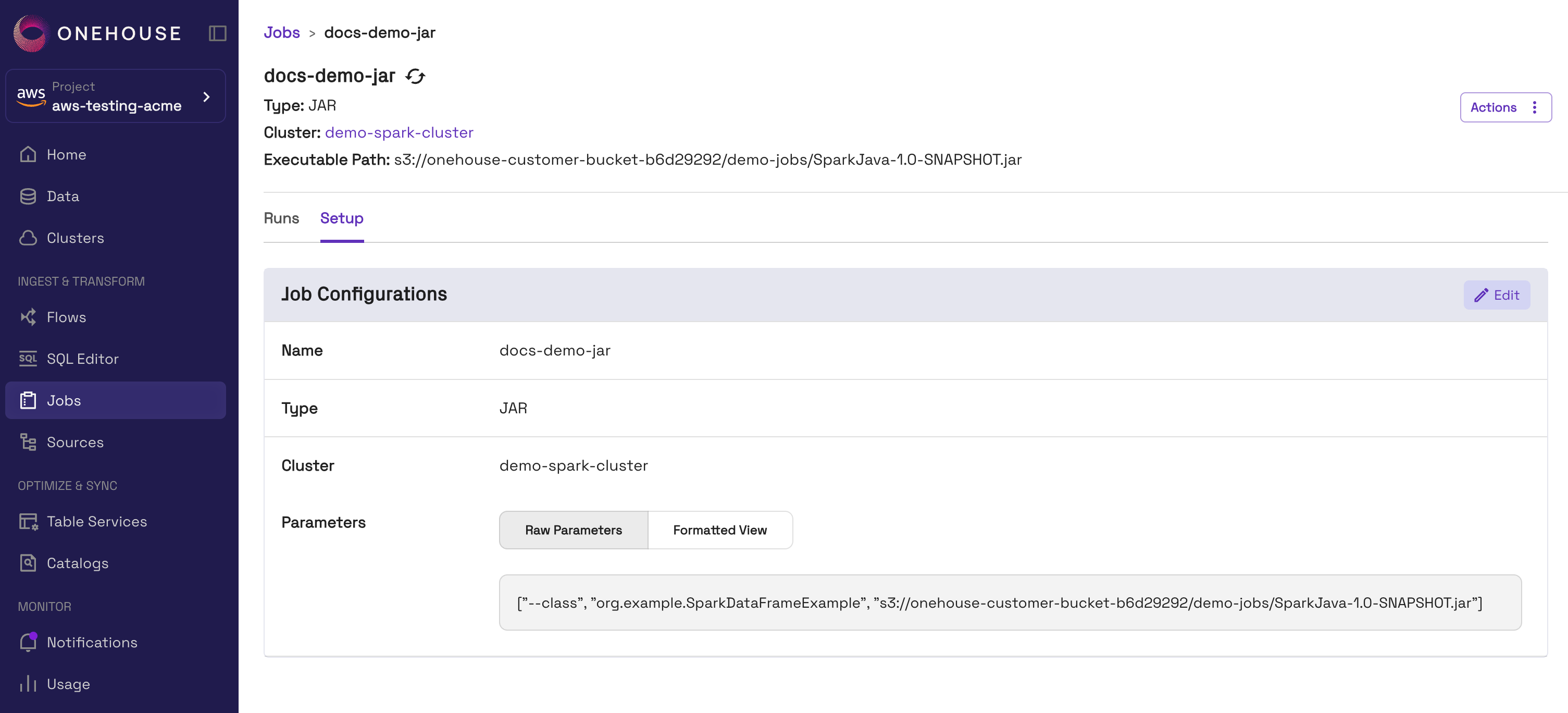
Step 2: Create the Job in Onehouse
- First, ensure you have the Project Admin role. This is currently a requirement for creating Jobs.
- In the Onehouse console, open Jobs and click Create Job.
- Configure the Job by filling in the following fields:
- Name: Specify a unique name to identify the Job.
- Type: Select 'JAR'.
- Parameters: Specify parameters for the Job, including the executable filepath and JAR class. Ensure you follow the JAR Job parameters guidelines. You can copy-paste the following parameters for the
SparkJavaexample, replacing the JAR path with your own:["--class", "org.example.SparkDataFrameExample", "s3://onehouse-customer-bucket-12345/demo-jobs/SparkJava-1.0-SNAPSHOT.jar"]
- Create the Job. This will not immediately run the Job.
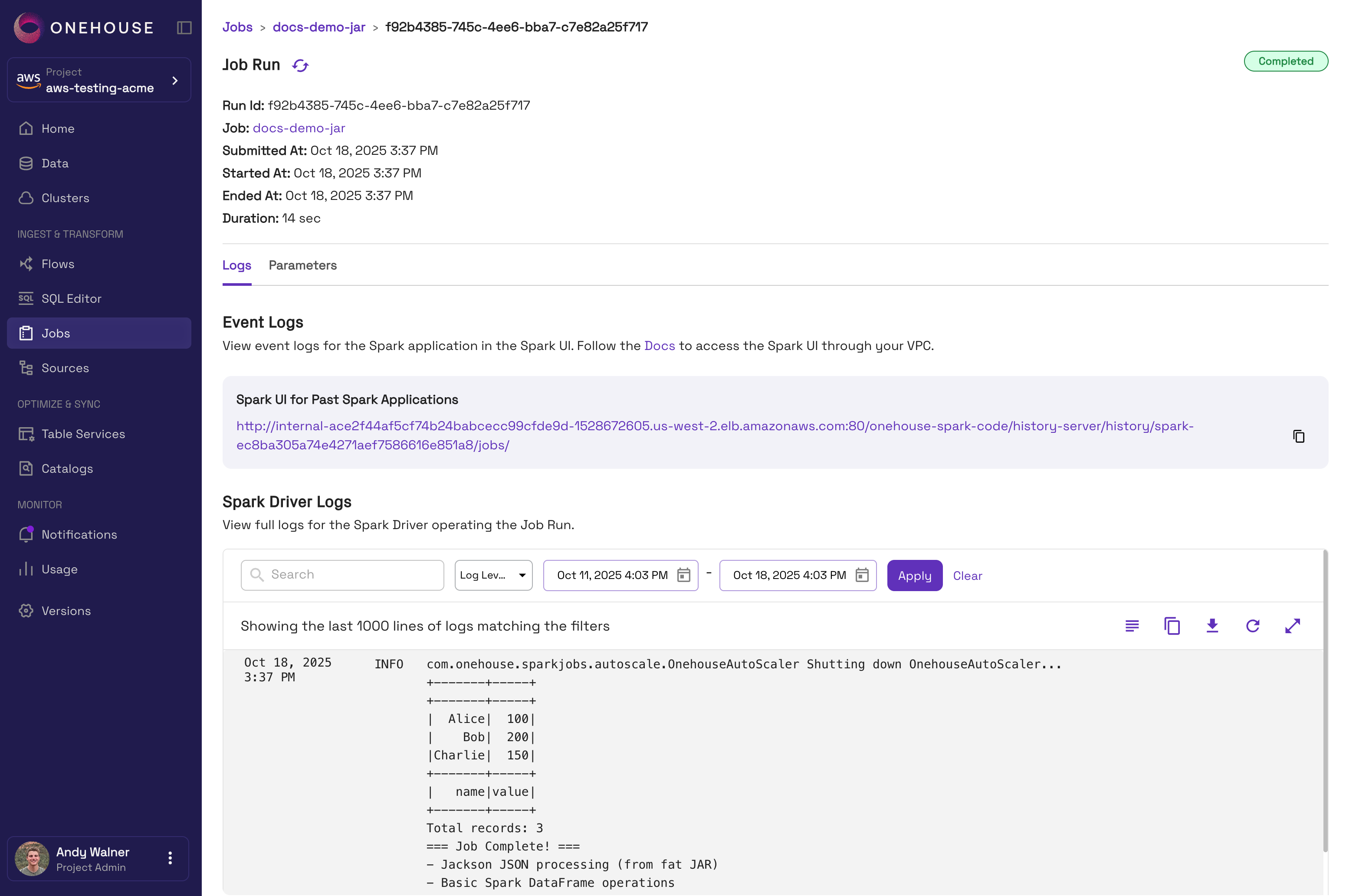
Step 3: Run the Job
After the Job is created, you can trigger a run. Learn more about running Jobs here.
- In the Onehouse console, navigate to the Jobs page.
- Open the Job you'd like to run, then click Actions > Run. You can also use the
RUN JOBAPI command. - When the Job starts running, you can view the driver logs in the Onehouse console by clicking into the Job run. Read more here on monitoring Job runs.
Configuring JAR Job parameters
You can configure the parameters for your Job as a JSON array of strings. You should include the required parameters, and be sure to add parameters in the proper order.
| Order | Parameter | Description |
|---|---|---|
| 1 | --class | The main class to execute (required for JAR jobs) |
| 2 | --conf | Optional Spark configuration properties (can be repeated) |
| 3 | /path/to/jar | The path to your executable JAR in Cloud Storage (required) |
| 4 | arg1, arg2, … | Arguments passed to your main class |
Example:
[
"--class", "com.example.MySparkApp",
"--conf", "spark.executor.memory=4g",
"--conf", "spark.executor.cores=2",
"/path/to/my-spark-app.jar",
"arg1", "--flag1"
]
Follow these guidelines to ensure your Jobs run smoothly:
- Add any
spark.extraListenersin parameters. Do not add these in your code directly. - If you are setting
spark.driver.extraJavaOptionsorspark.executor.extraJavaOptions, you must add"-Dlog4j.configuration=file:///opt/spark/log4j.properties". - Do not set the following Apache Spark configurations:
- spark.kubernetes.node.selector.*
- spark.kubernetes.driver.label.*
- spark.kubernetes.executor.label.*
- spark.kubernetes.driver.podTemplateFile
- spark.kubernetes.executor.podTemplateFile
- spark.metrics.*
- spark.eventLog.*
Managing Library Dependencies
You may install Java Maven or Gradle libary dependencies for your Jobs. Dependencies are installed by each Job's driver, rather than at the Cluster-level, to prevent dependency conflicts between Jobs running on the same Cluster.
Pre-Installed Libraries
The following libraries come pre-installed on every 'Spark' Cluster:
- Apache Spark 3.5.2
- Apache Hudi 0.14.1
- Apache Iceberg 1.10.0 (only if the Cluster uses an Iceberg REST Catalog)
In the build.gradle file for your Job, you should import pre-installed libraries as compileOnly dependencies. This keeps your JAR size small and prevents version conflicts.
Example:
dependencies {
compileOnly group: "org.apache.hudi", name: "hudi-spark3.5-bundle_2.12", version: "0.14.1"
}
Install Libraries for JAR Jobs
You may upload any Java libraries as JAR files to your cloud storage bucket, then reference them in the Job parameters. Below are the steps to do this:
- Upload your dependencies as JAR files to a cloud storage bucket that Onehouse can access.
- When you create a Job, reference the JAR files in the Job Parameters with
"--conf", followed by"spark.jars=<JARS>". Example:"--class", "com.example.MyApp", "--conf", "spark.jars=s3a://path/to/dependency1.jar,s3a://path/to/dependency2.jar", "s3a://path/to/myapp.jar"