Ray
Ray enables AI practitioners to natively distribute Python programs, combine CPU and GPU workloads, perform ML model training/tuning/serving, and much more. Ray can read from Onehouse tables to incorporate structured and semi-structured data into your AI, ML, and data science workloads. For example, you may build a RAG-based application that leverages vector embeddings stored on Onehouse.
Set up CPU and GPU Capacity
Ray Clusters allow you to run CPU and GPU instances together, sharing data between both instance types. The default GPU instance types are g5.xlarge on AWS and g2-standard-4 on GCP.
For each Ray Cluster, you will configure min/max CPU units and max GPU units. A CPU unit is equivalent to one CPU instance and a GPU unit is equivalent to one GPU instance. Each CPU unit and GPU unit counts as one OCU, and Onehouse calculates the min/max OCU from your configured CPU and GPU units (though Open Engines OCU will not be billed currently).
Submit Ray Jobs
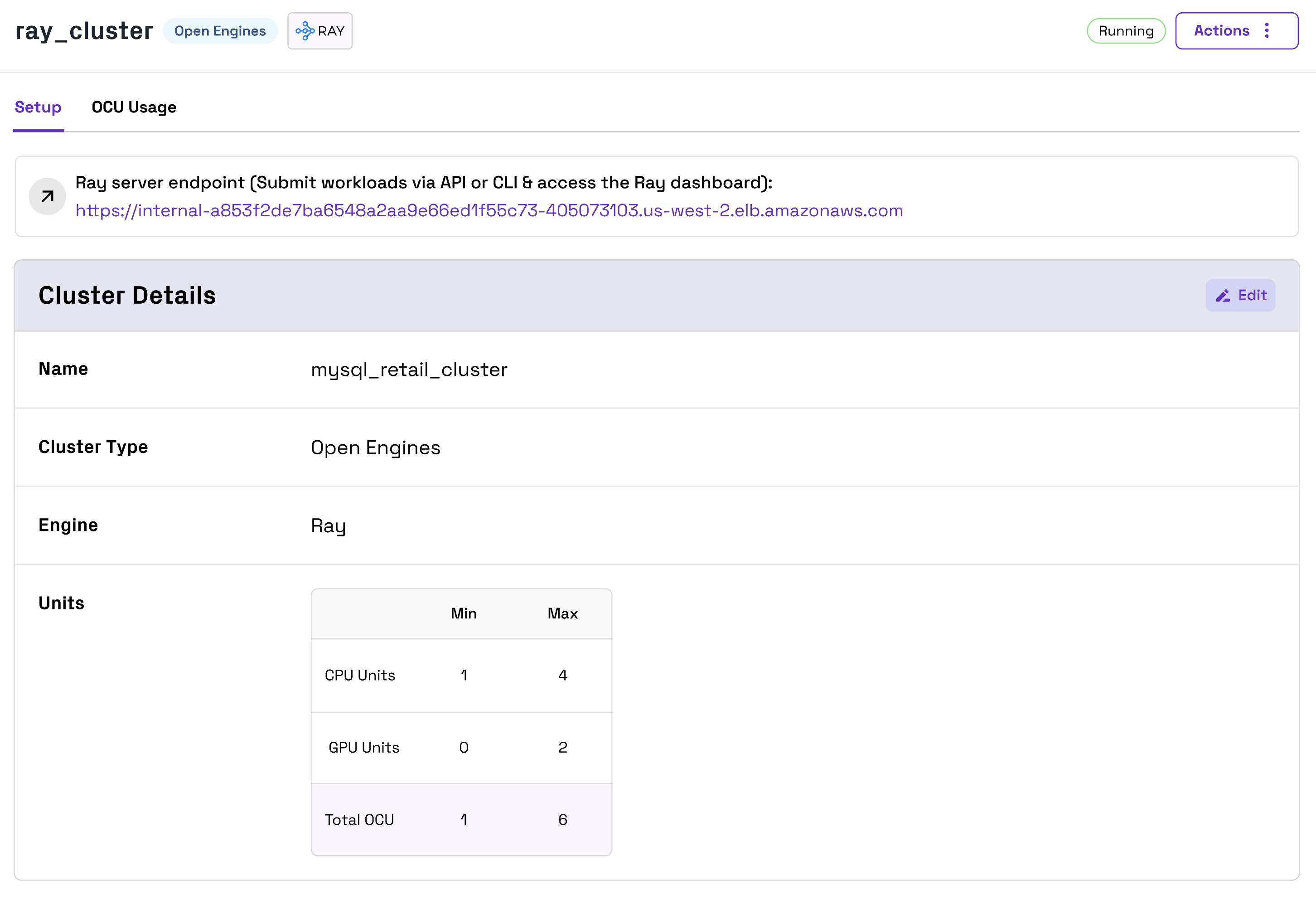
You can submit workloads with the Ray Jobs API or CLI via the Ray server endpoint found in the Onehouse console. This endpoint is accessible from within the VPC.
Monitor Ray Jobs
You can monitor Ray workloads in the Ray dashboard via the same Ray server endpoint for submitting workloads. To access the dashboard, you can port forward on port 8265 to the Ray server endpoint you retrieved from the Onehouse console, then open 127.0.0.1:8265 in your browser.
Example: Run a Ray job
First, create your Ray job as a local .py file. For this example, we will name it task.py.
import ray
import requests
@ray.remote
def get_requests_version():
storage_options = {"aws_region": "us-west-2"}
tableUri = "s3a://onehouse-customer-bucket-5997658f/open-engines/open_engine_lake_default/oh_datagen_events_clickstream/v1"
ray.data.read_hudi(table_uri=tableUri,storage_options=storage_options).show(20)
return requests.__version__
ray.init()
print("requests version:", ray.get(get_requests_version.remote()))
Next, open your Ray Cluster in the Onehouse console and copy the Ray server endpoint.
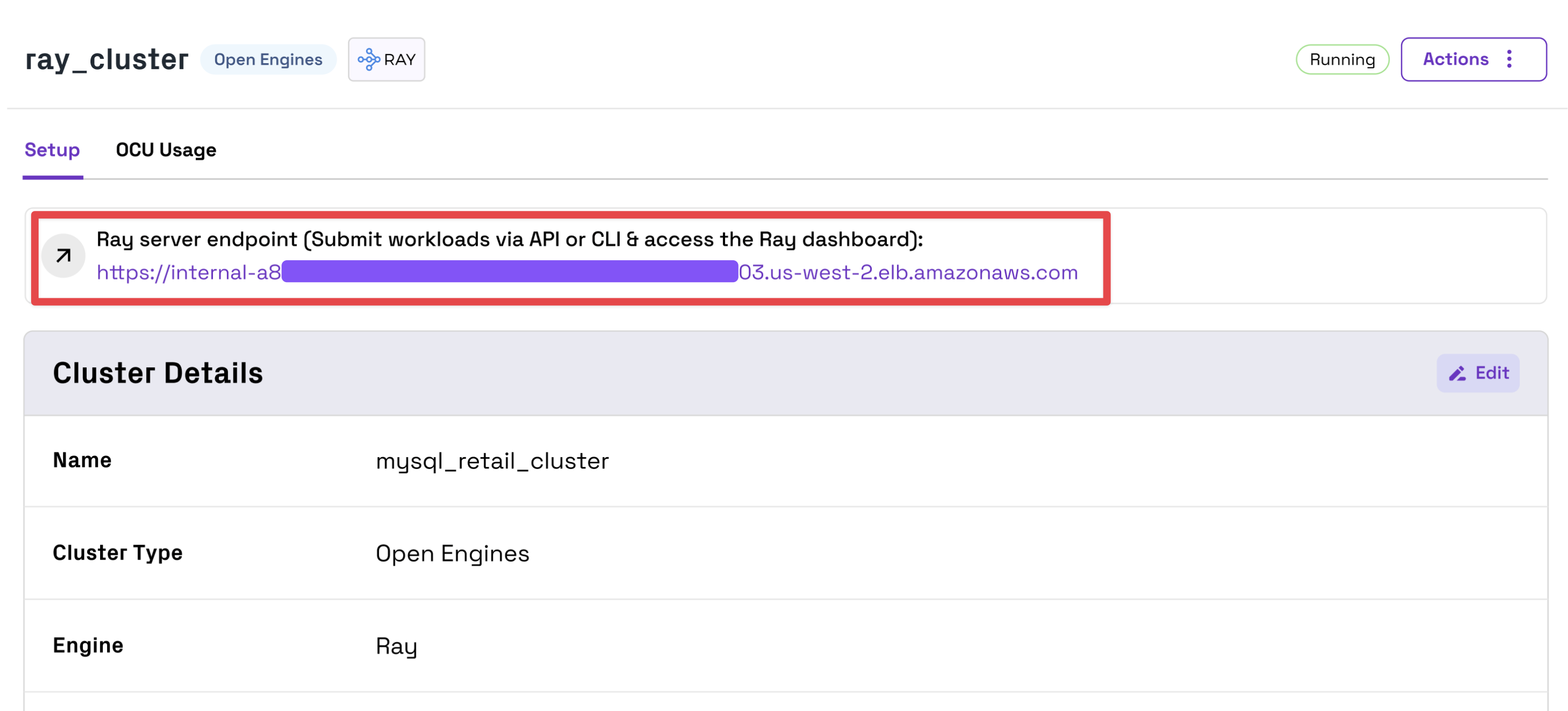
The Ray Cluster is only accessible from within your VPC. To access the Cluster locally, you must use a VPN or use SSH connect through a bastion host.
Port forward to the endpoint you copied from the Onehouse console. Below is an example of how you can do this through an SSH tunnel with a bastion host:
# Example structure via bastion host
ssh -N ec2-user@<bastion-host-IP> -L 8265:<ray-cluster-endpoint>:8265
# Example command via bastion host
ssh -N ec2-user@35.89.130.210 -L 8265:internal-acf7eef90a4724044872ee27470785fa-1653546594.us-west-2.elb.amazonaws.com:8265
After you have port forwarded to the Ray server in your local environment, set the Ray address to localhost port 8265. Then, use the Ray CLI to submit your Ray job. Be sure to install the "hudi" libarary if you are reading from Hudi tables.
export RAY_ADDRESS="http://127.0.0.1:8265"
ray job submit --working-dir . --runtime-env-json='{"pip": ["hudi"]}' -- python task.py
Below is another example of doing this in a single step, also passing the Ray address along with other command-line arguments.
ray job submit --num-gpus=2 --runtime-env-json='{"pip": ["hudi"]}' --address http://localhost:8265 -- python -c "import ray; storage_options = {\"aws_region\": \"us-west-2\"}; tableUri = \"s3a://onehouse-customer-bucket-5997658f/open-engines/open_engine_lake_default/oh_datagen_events_clickstream/v1\"; ds = ray.data.read_hudi(table_uri=tableUri,storage_options=storage_options);print(ds.show())"