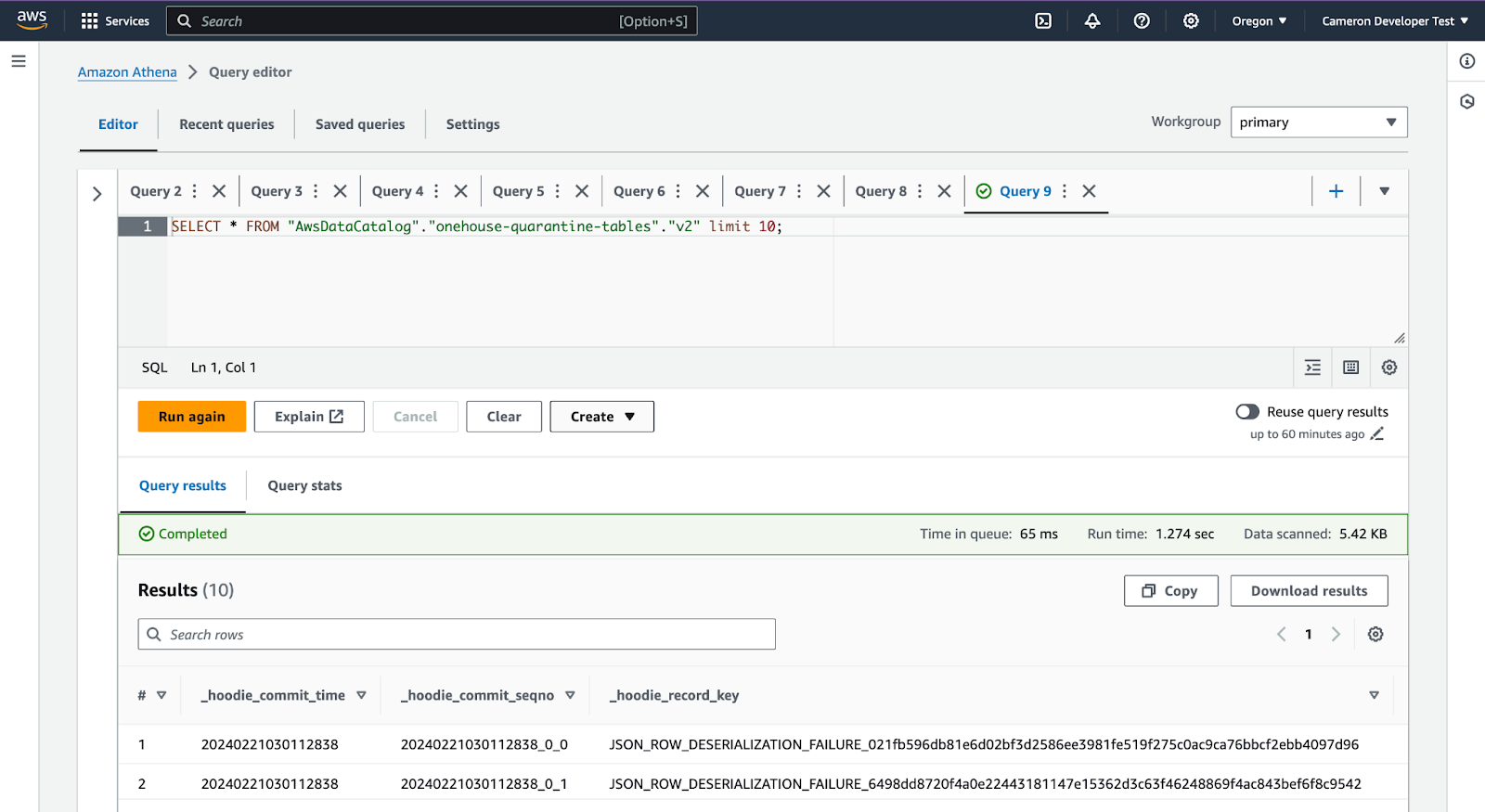
Examine Onehouse quarantine tables with AWS Glue and Athena
Problem: On AWS, Onehouse quarantine tables don’t have Glue metadata so that they cannot be queried using Athena.
Solution: By using AWS Glue crawlers and Amazon Athena, you can discover the schema and partitioning of Hudi tables, and create the metadata.
Overview
- Create an AWS Glue Crawler: Configure an AWS Glue crawler to target the S3 path where the Hudi tables are located. You can specify the maximum depth for the crawler to traverse the S3 paths.
- Run the AWS Glue Crawler: Execute the crawler to inspect the S3 paths. The crawler will catalog the schema information, including new tables, schema updates, and partition information, in the AWS Glue Data Catalog.
- View the Hudi Table Definition: After the crawler run is complete, you can view the Hudi table definition in the AWS Glue console. The crawler will create table definitions for both read-optimized and real-time tables if applicable (e.g.,
sample_hudi_mor_table_rofor read-optimized andsample_hudi_mor_table_rtfor real-time). - Query with Amazon Athena: With the table definitions created in the AWS Glue Data Catalog, you can now open the Amazon Athena console and start querying the Hudi tables using standard SQL queries.
Visual Steps
Go to AWS Glue, and choose 'Crawlers' in the left menu pane. Then, click 'Create crawler'.
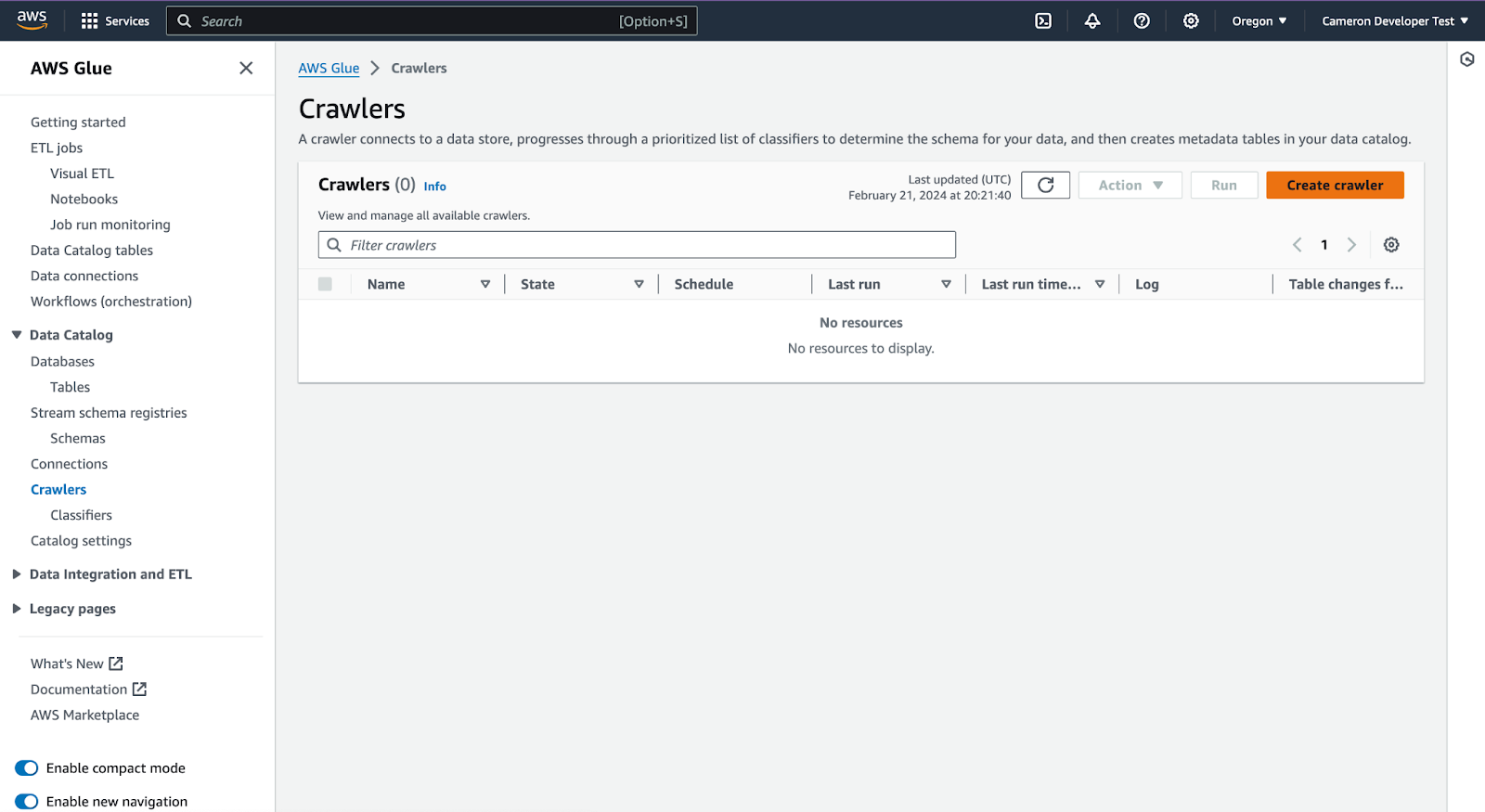
Enter the crawler name, ex: Onehouse quarantine data, click 'Next'
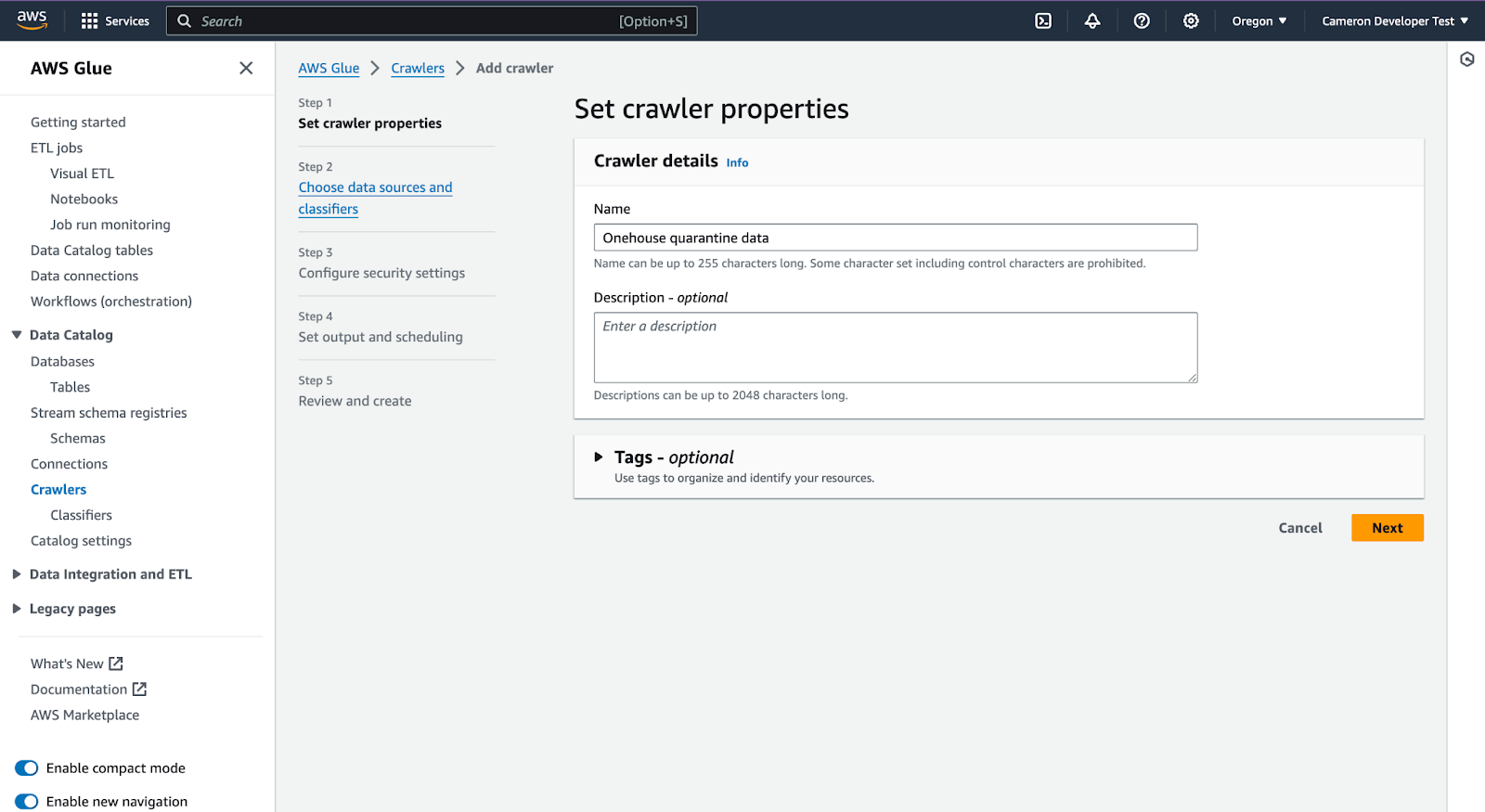
Click 'Add a data source'
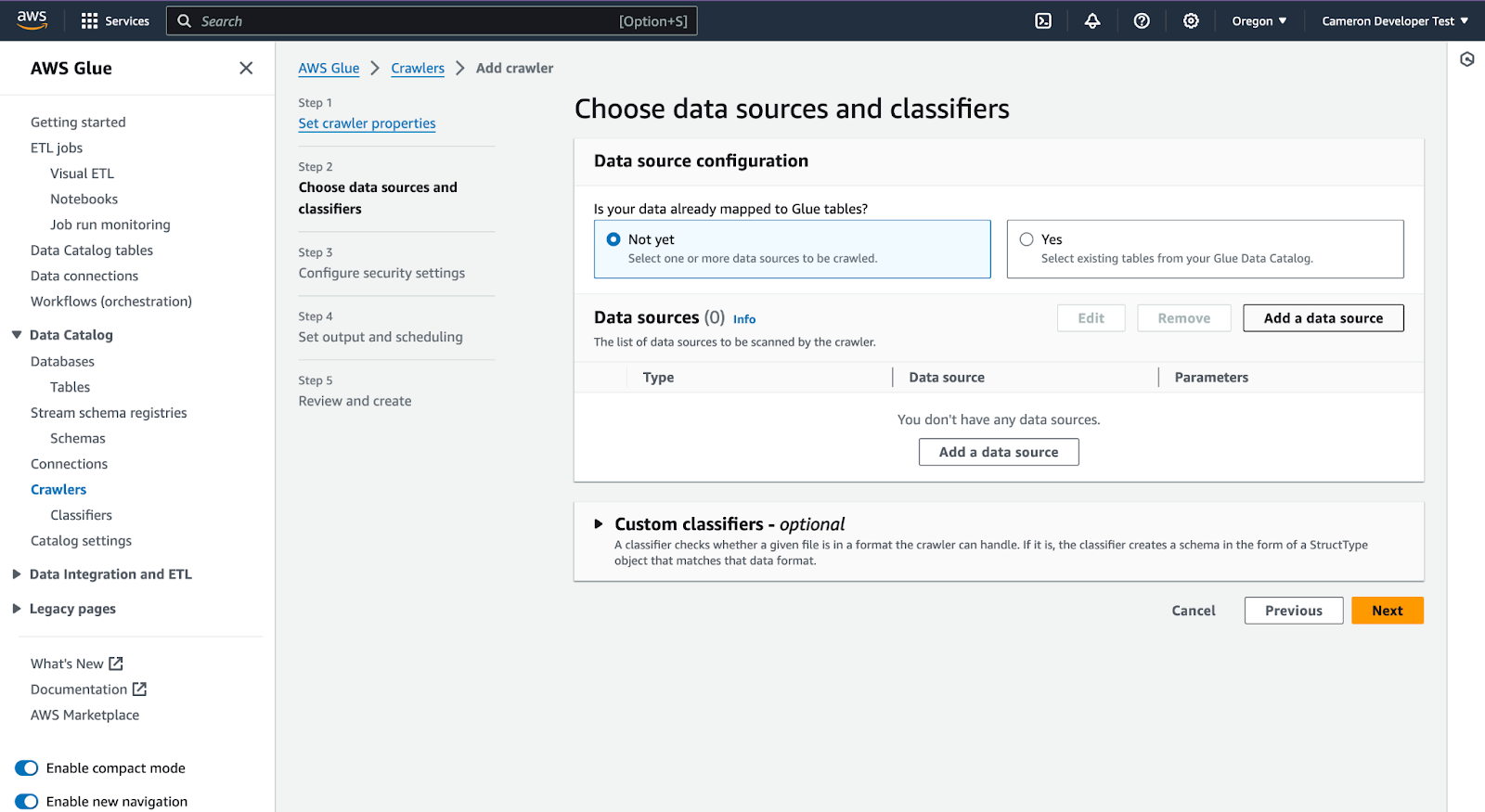
Add data source – specify Hudi in S3
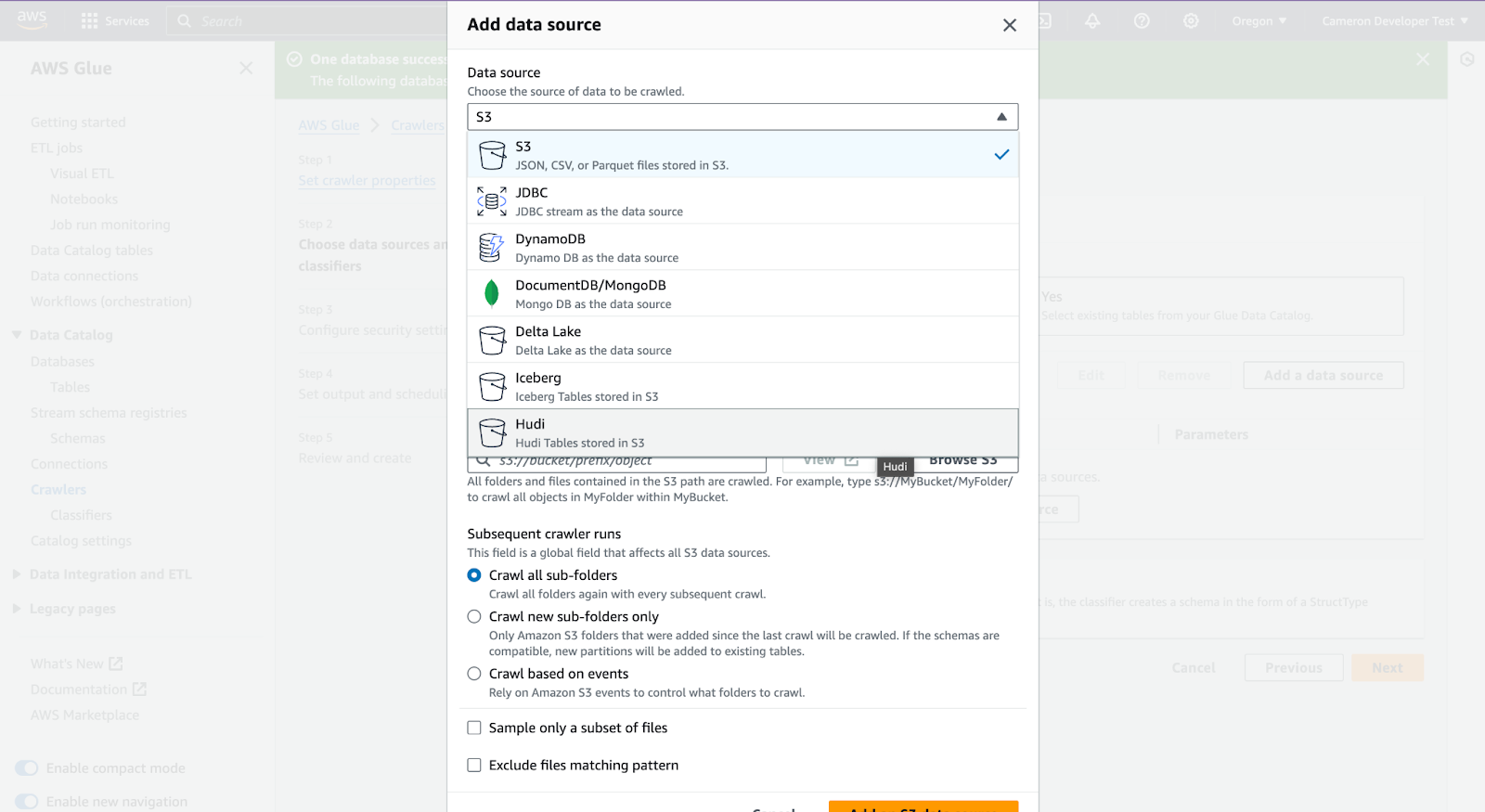
Add your s3 path, this will be your Onehouse customer bucket, datalake folder and Onehouse database name, like: s3://onehouse-customer-bucket-c61092fc/datalake/acme_retail_bronze/. Then click 'Add a Hudi data source'.
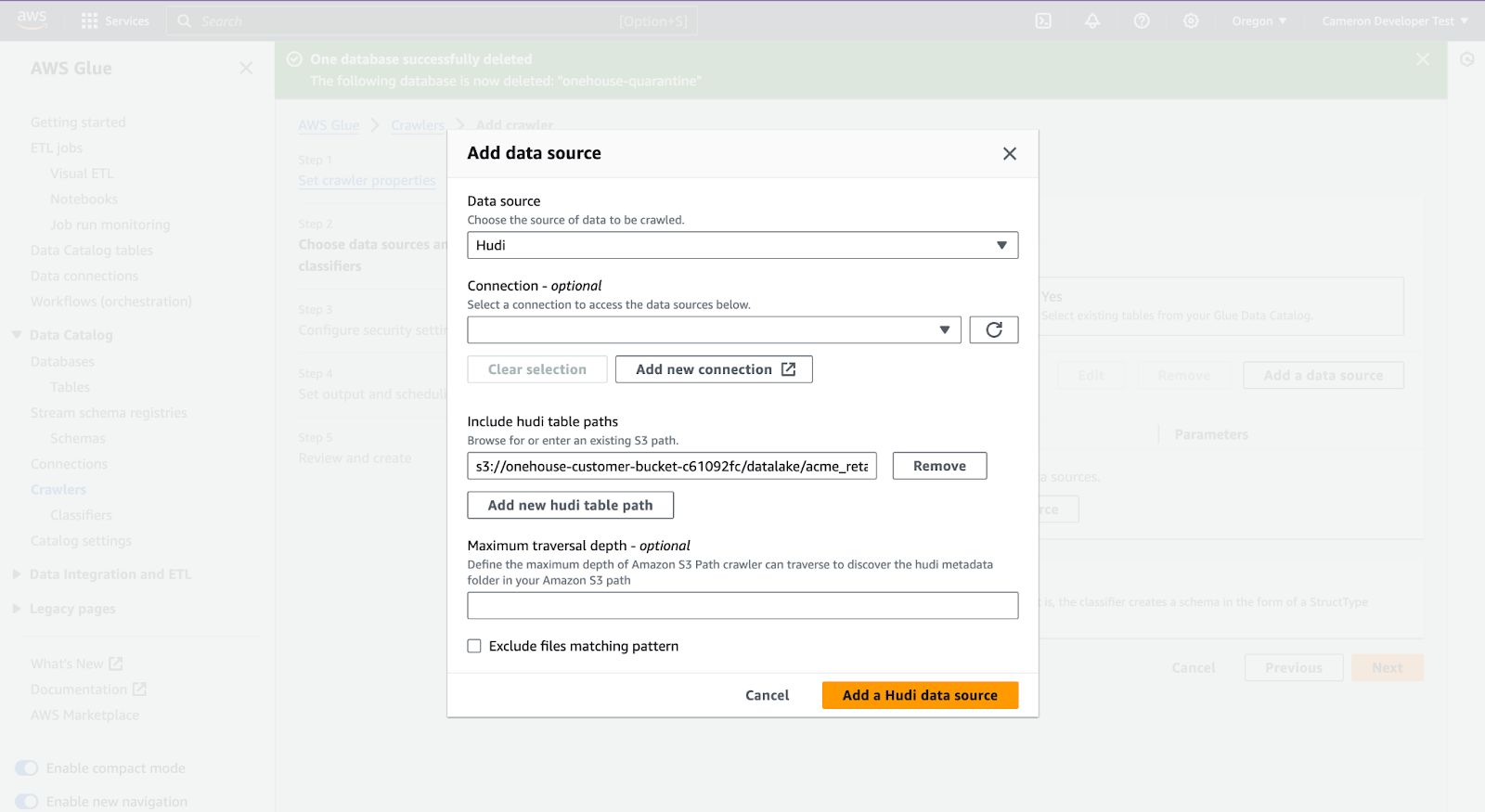
Click 'Next'
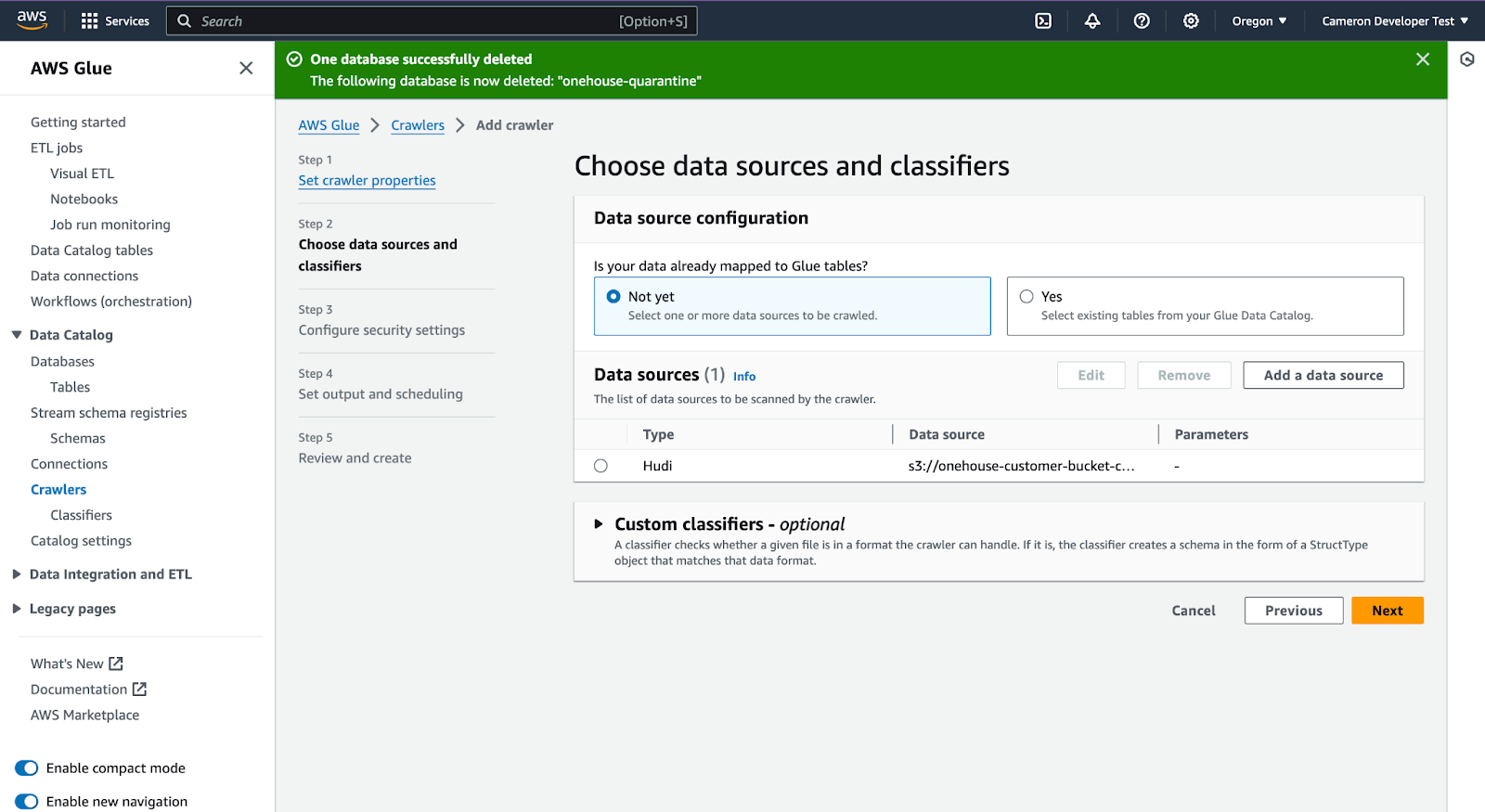
If already have a role named '"Implementing Stream Processing on the Data Lakehouse for High Performance, Operational Efficiency and Cost Savings." ' choose it, otherwise, click 'Create new IAM role' (it will be configured automatically).
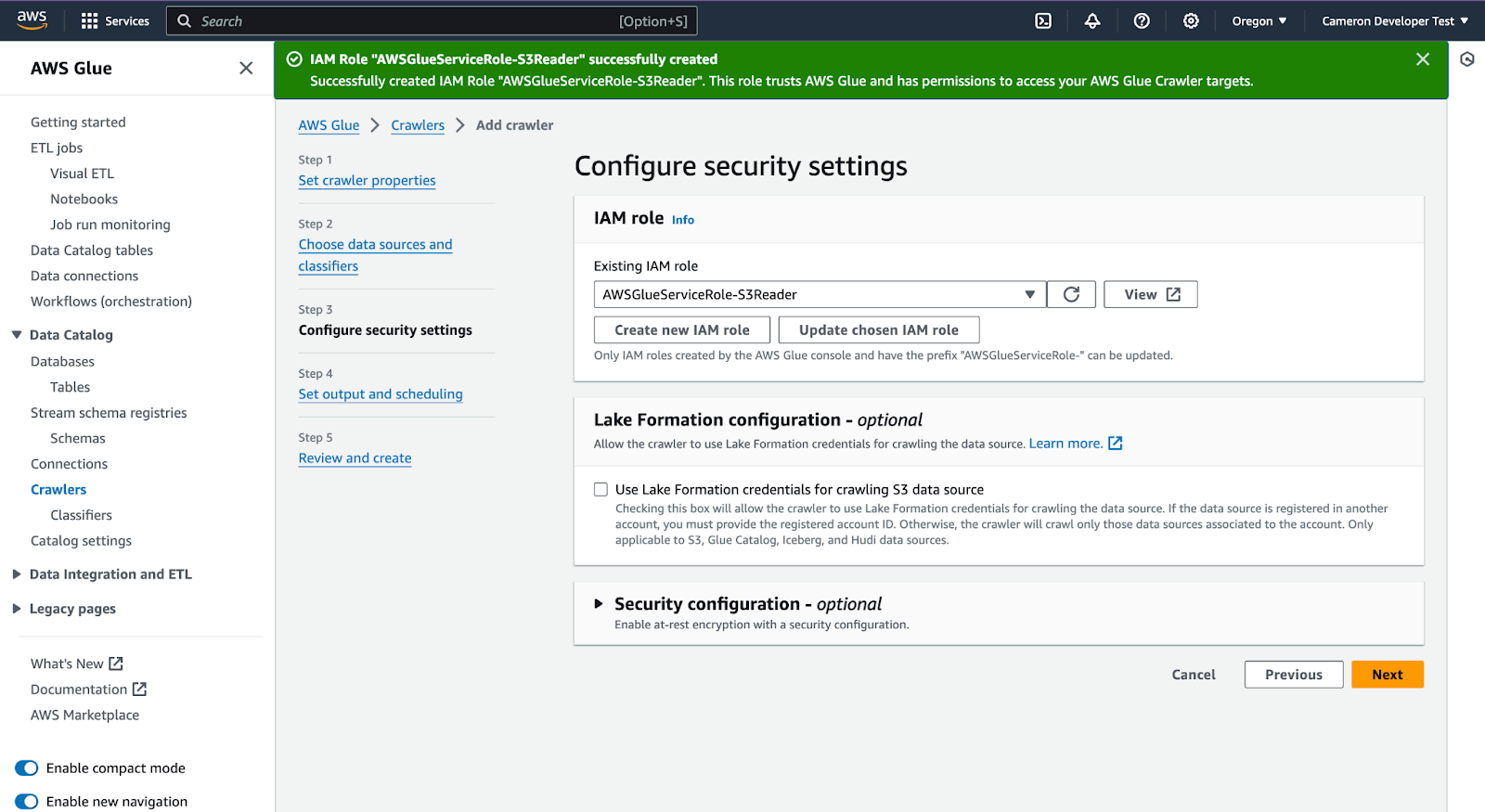
In Step 4 'Set output and scheduling' click 'Add database'. Then enter the database name, 'onehouse-quarantine' and 'Create database'.
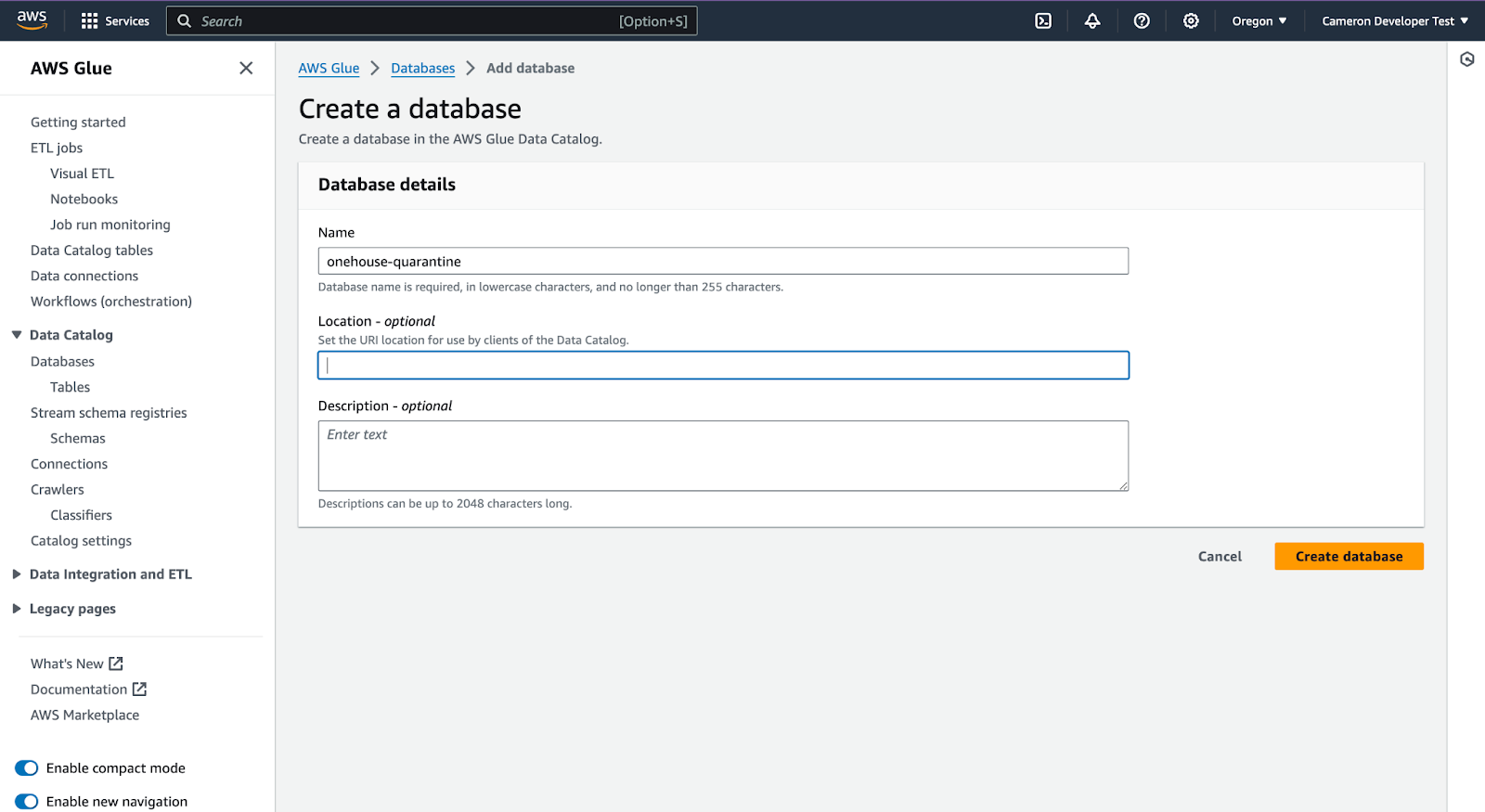
Back on the 'Set output and scheduling' tab, click the refresh spinner, and select the newly created target database. Click Next…
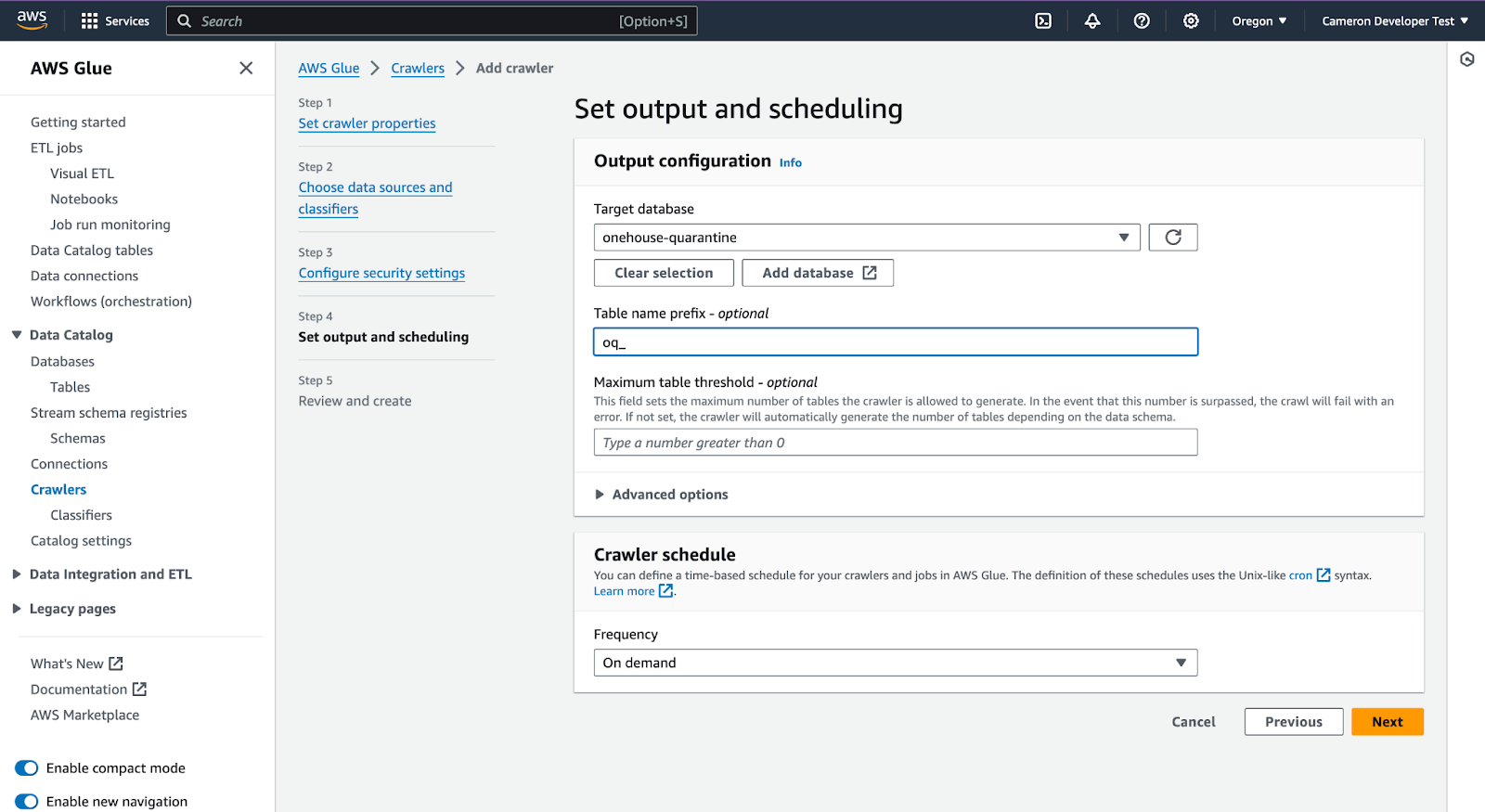
Scroll down and click 'Create'
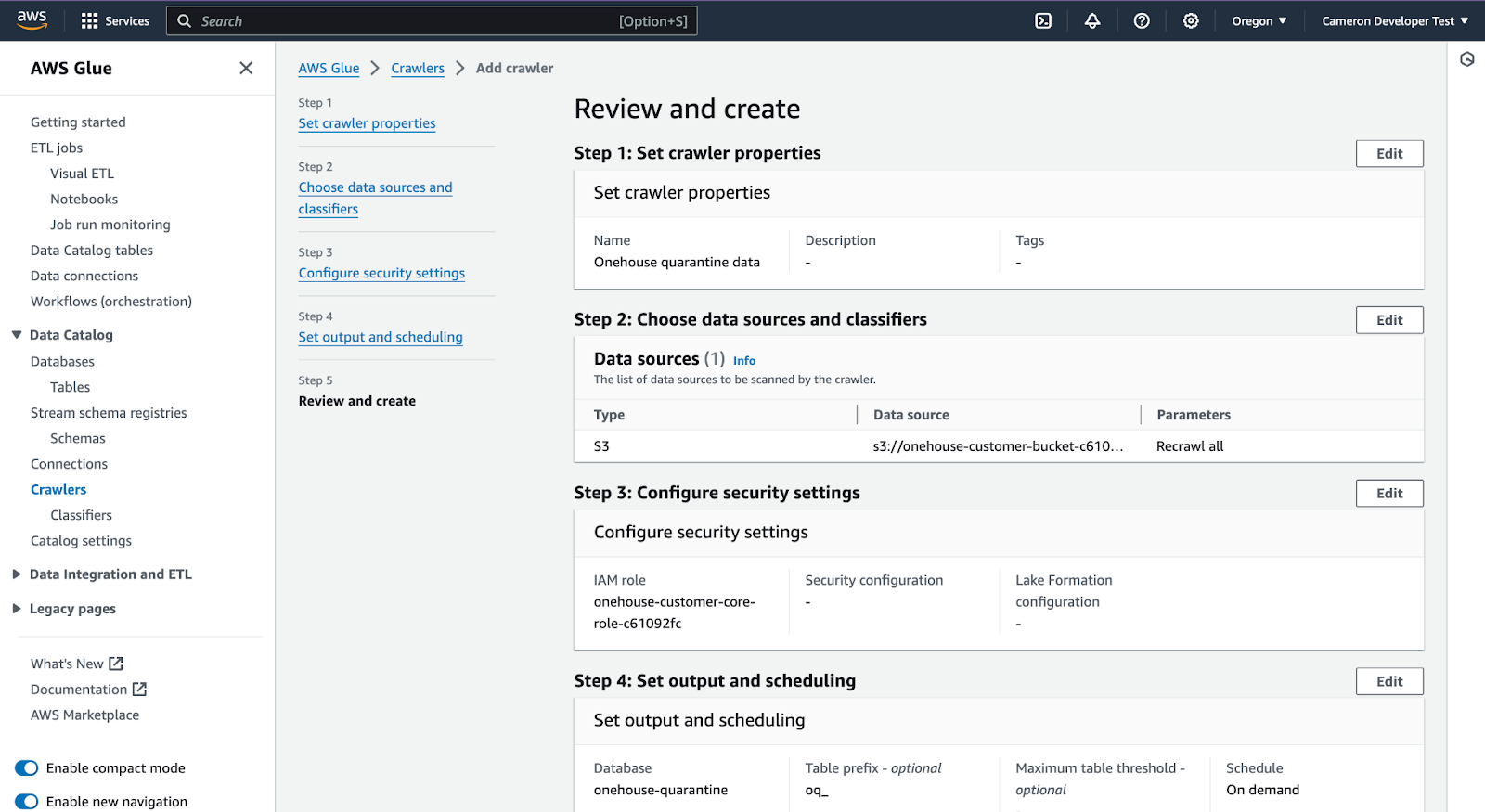
Run crawler. It takes 5-10 minutes.
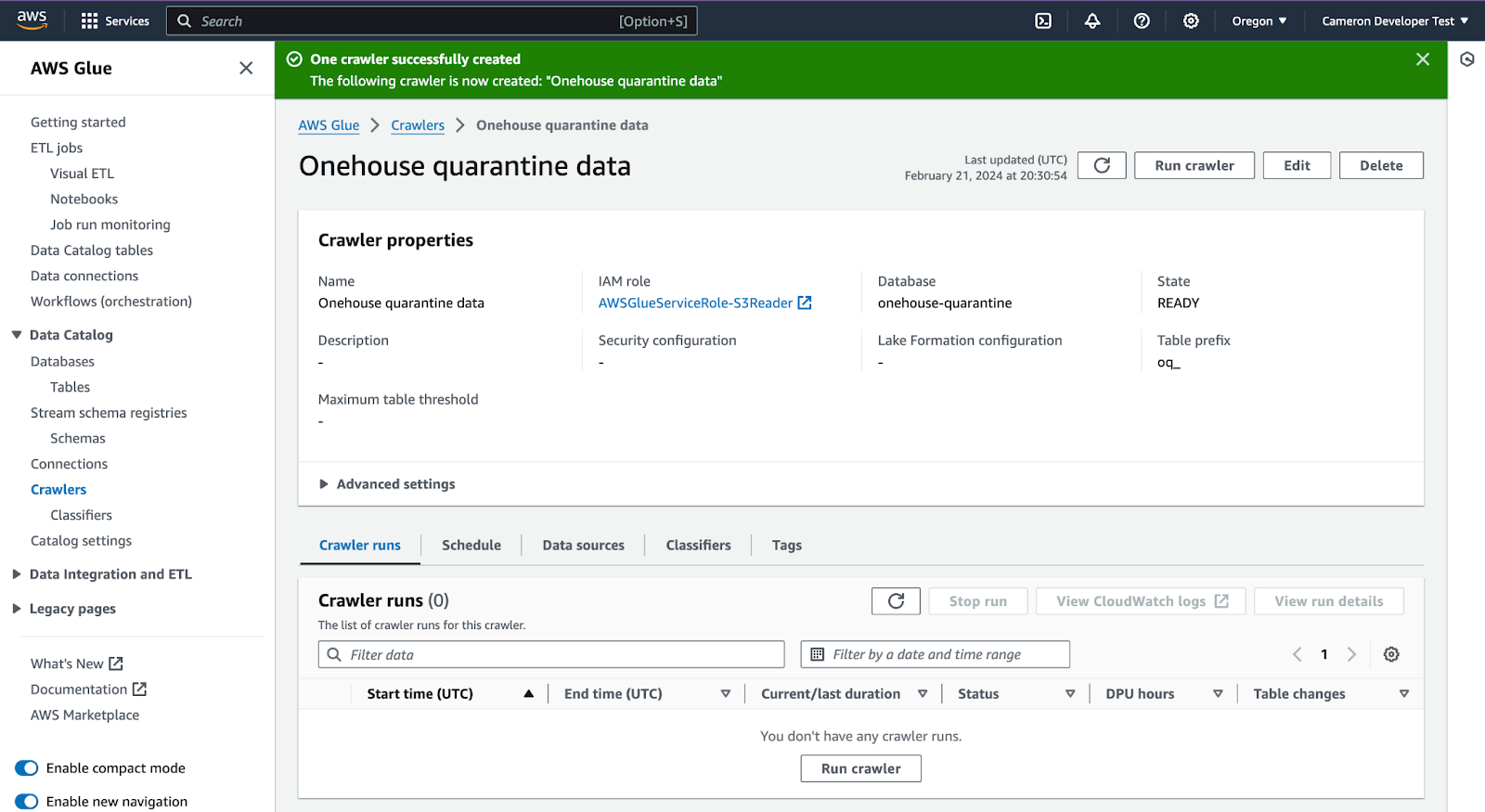
In Glue, open the database you created to view the quarantine tables
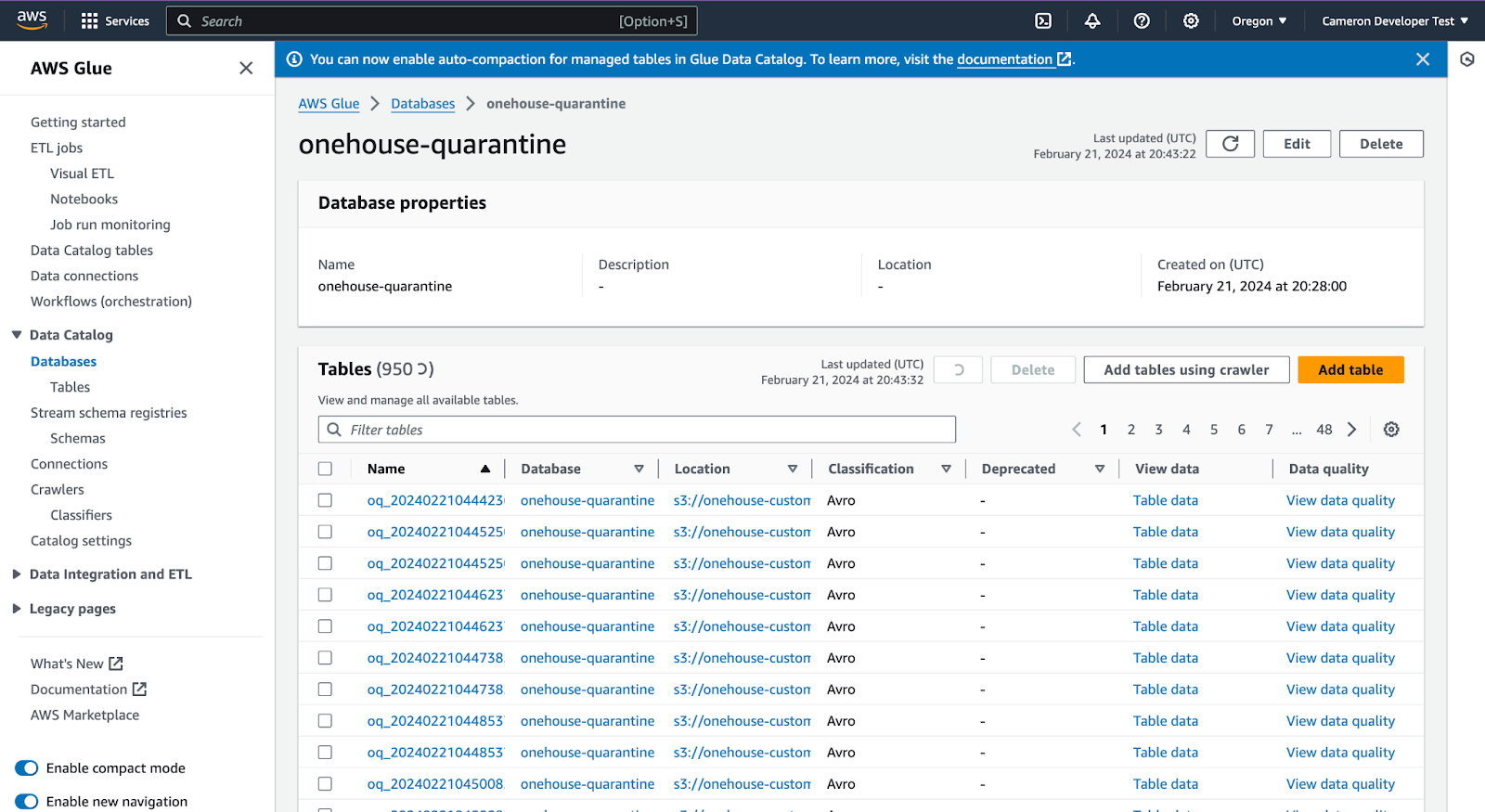
Click into the database to the current version
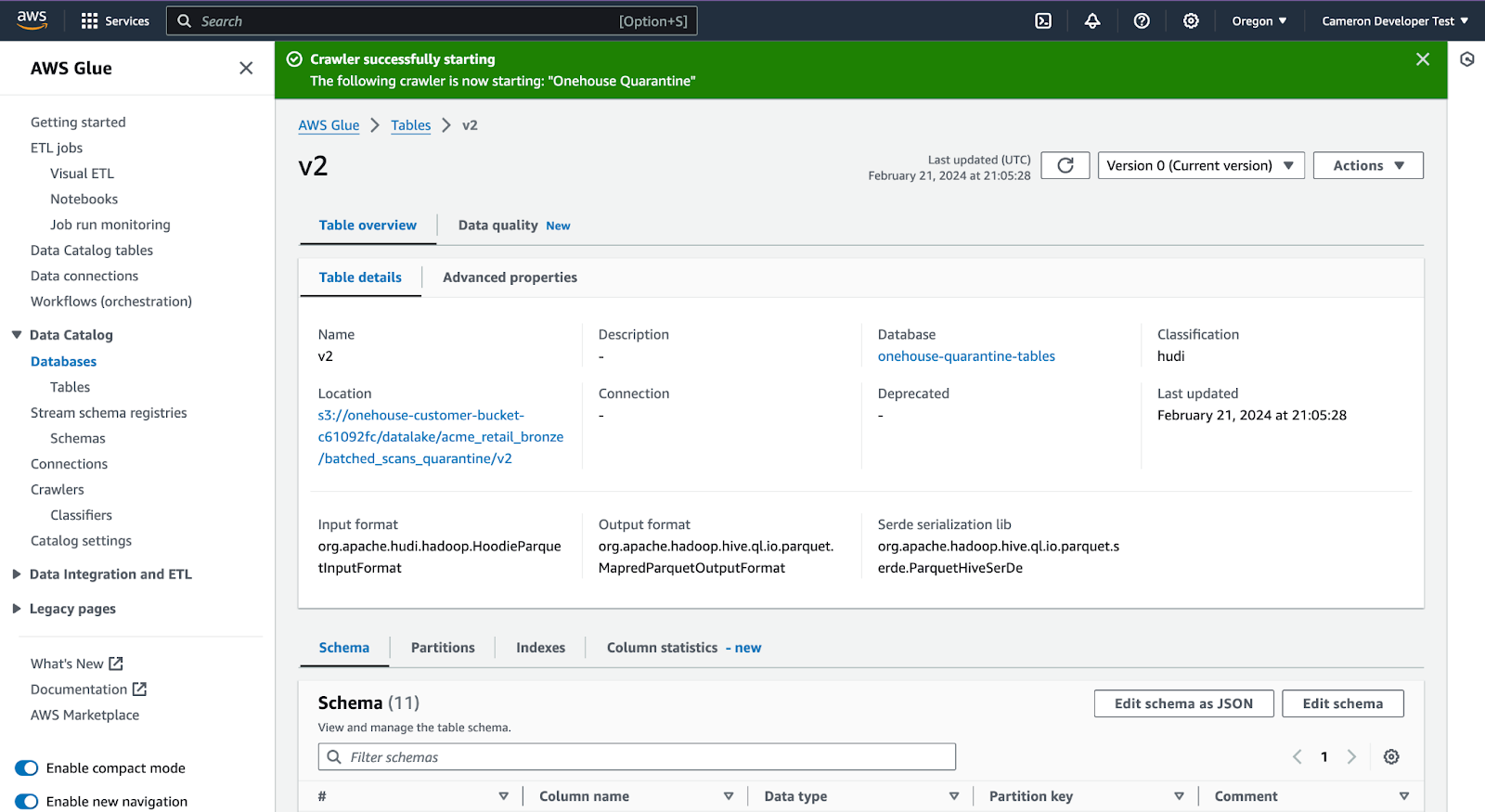
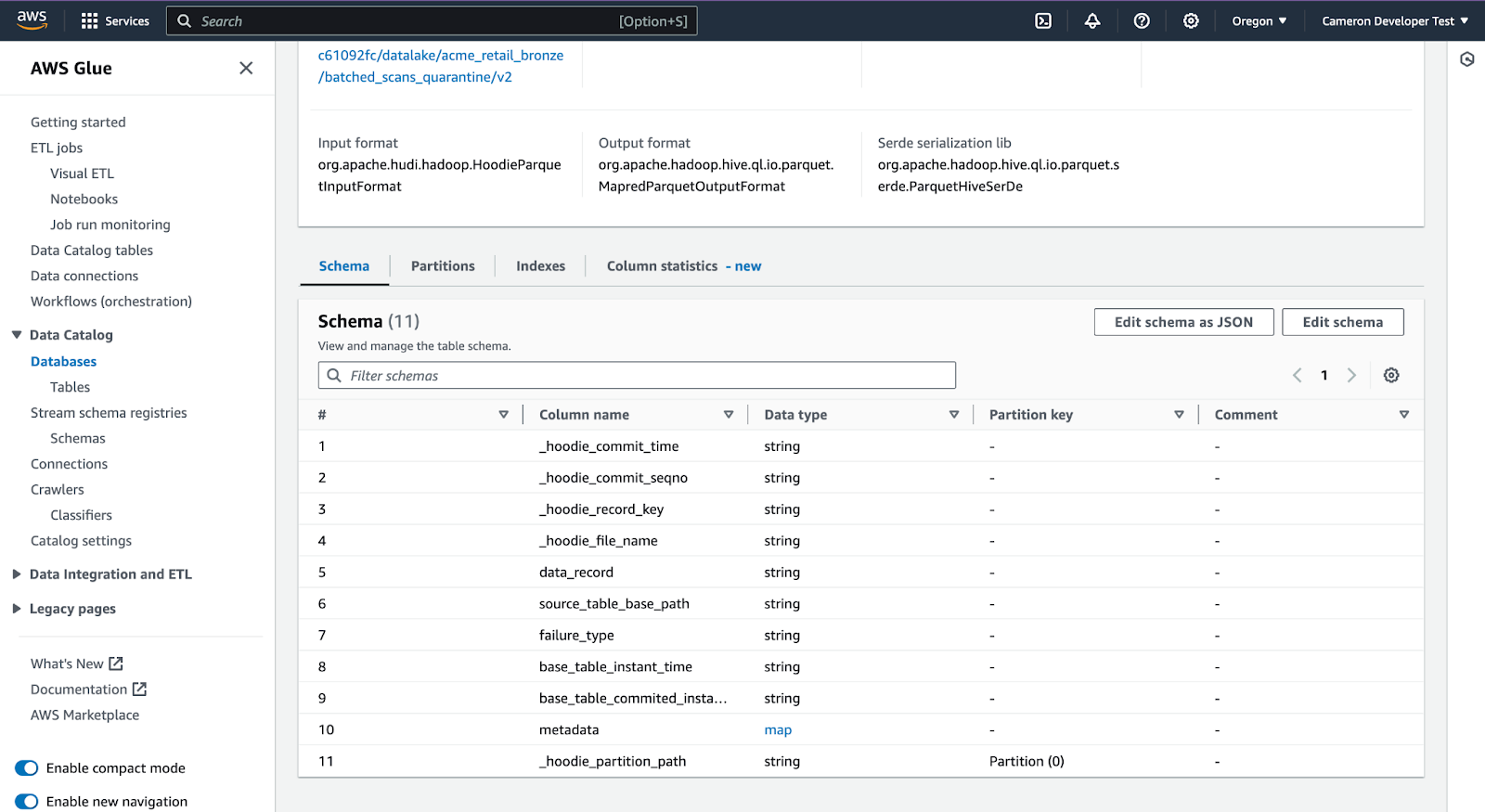
Scroll down to see the schema
Click ‘View Data’
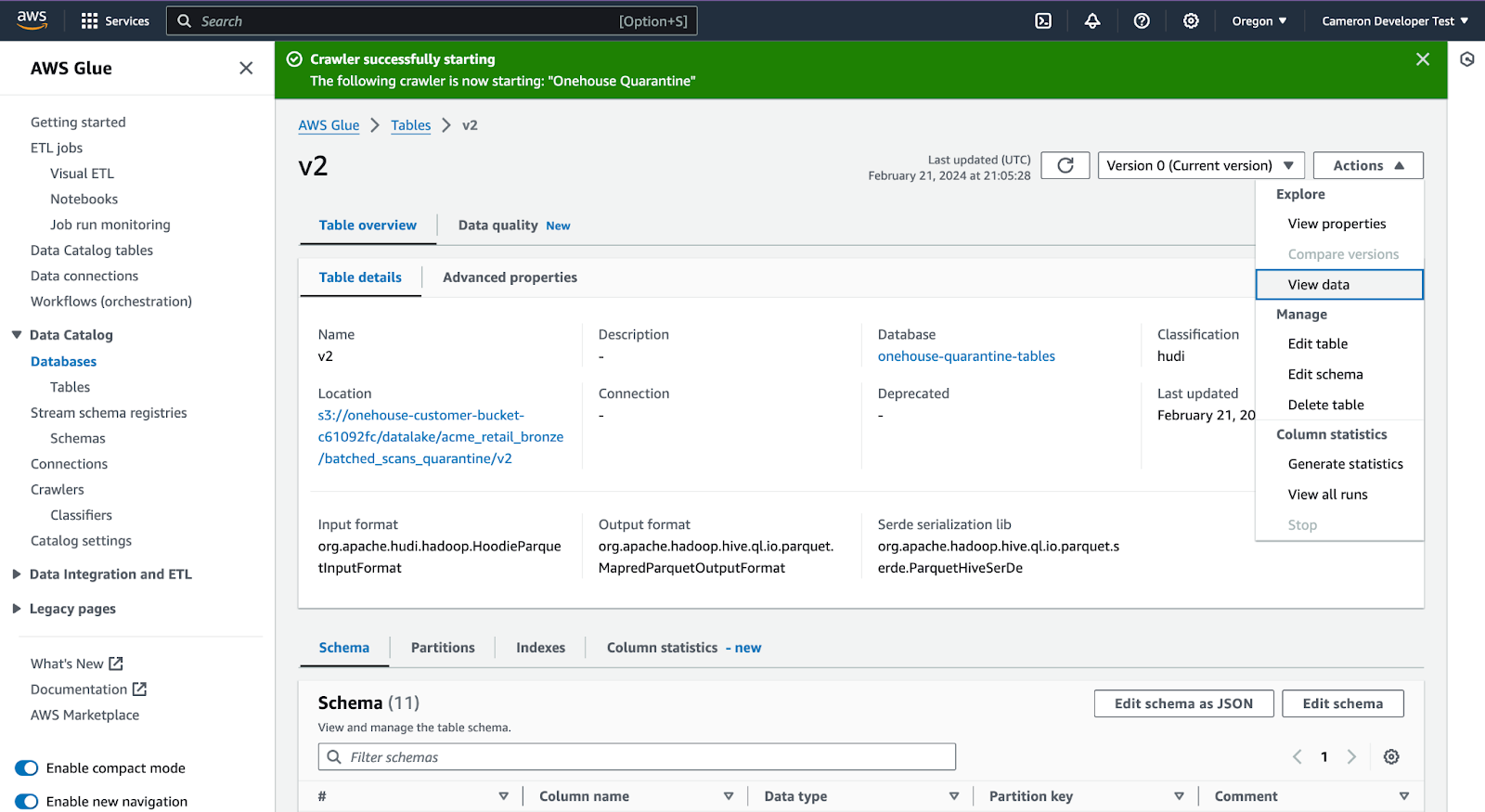
A select statement is prefilled, and you can examine the quarantine rows