Advanced Monitoring
Onehouse offers advanced monitoring that provides rich metrics about your deployment by exposing a prometheus server and pre-built Grafana dashboards within your cloud environment.
This guide walks through the advanced monitoring metrics and how to access them.
Get Access to Advanced Monitoring
To enable advanced monitoring for your project, contact the Onehouse team. You will receive a URL to access the load balancer hosting prometheus and Grafana.
By default, advanced monitoring is exposed on an internal load balancer, only accessible from within your VPC. Follow these steps to connect to the internal load balancer.
If public access is enabled for the project, you can directly access the load balancer from your public network after authenticating with your Onehouse account. For projects with public access enabled, the event logs URL will start with https://dp-apps.cloud.onehouse.ai/.
Prometheus
To access the prometheus server, open <load-balancer-url>/prometheus/query in your browser.
Prometheus is an open source time series database containing metrics about your Onehouse project and resources. You can query metrics directly in your browser with the prometheus console.
Grafana
To access the Grafana server, open <load-balancer-url>/grafana in your browser.
Grafana is an open source observability tool that can build charts and alerts from the prometheus metrics in your Onehouse project. Onehouse pre-creates useful Grafana charts out-of-the-box.
Pre-built Grafana charts
After you've received access to Prometheus, you can pull the metrics into a self-managed Grafana instance within your environment.
Onehouse will provides a Grafana with useful charts out-of-the-box. In the Grafana dashboard, you will find charts for the following use cases.
Configure Grafana Alerts
You can also configure custom Grafana alerts that are triggered by your Onehouse metrics. Follow these Grafana docs to configure alerts.
Get started with the following alert query templates:
- Alert on >3 consecutive lags for a stream
Or to exclude a table:
sum by(table, database) (ohds_deltastreamer_numConsecutiveSyncLags) > 3You can exclude multiple databases or tables by usingsum by(table, database) (ohds_deltastreamer_numConsecutiveSyncLags{database!="database_name", table!="table_name"}) > 3|to separate the different values - Alert when an in-progress sync is taking >3x longer than the configured sync frequency
(sum by(table, database) (ohds_deltastreamer_syncDurationSecs))/(sum by(table, database) (ohds_deltastreamer_syncIntervalSecs)) > 3
Use Cases
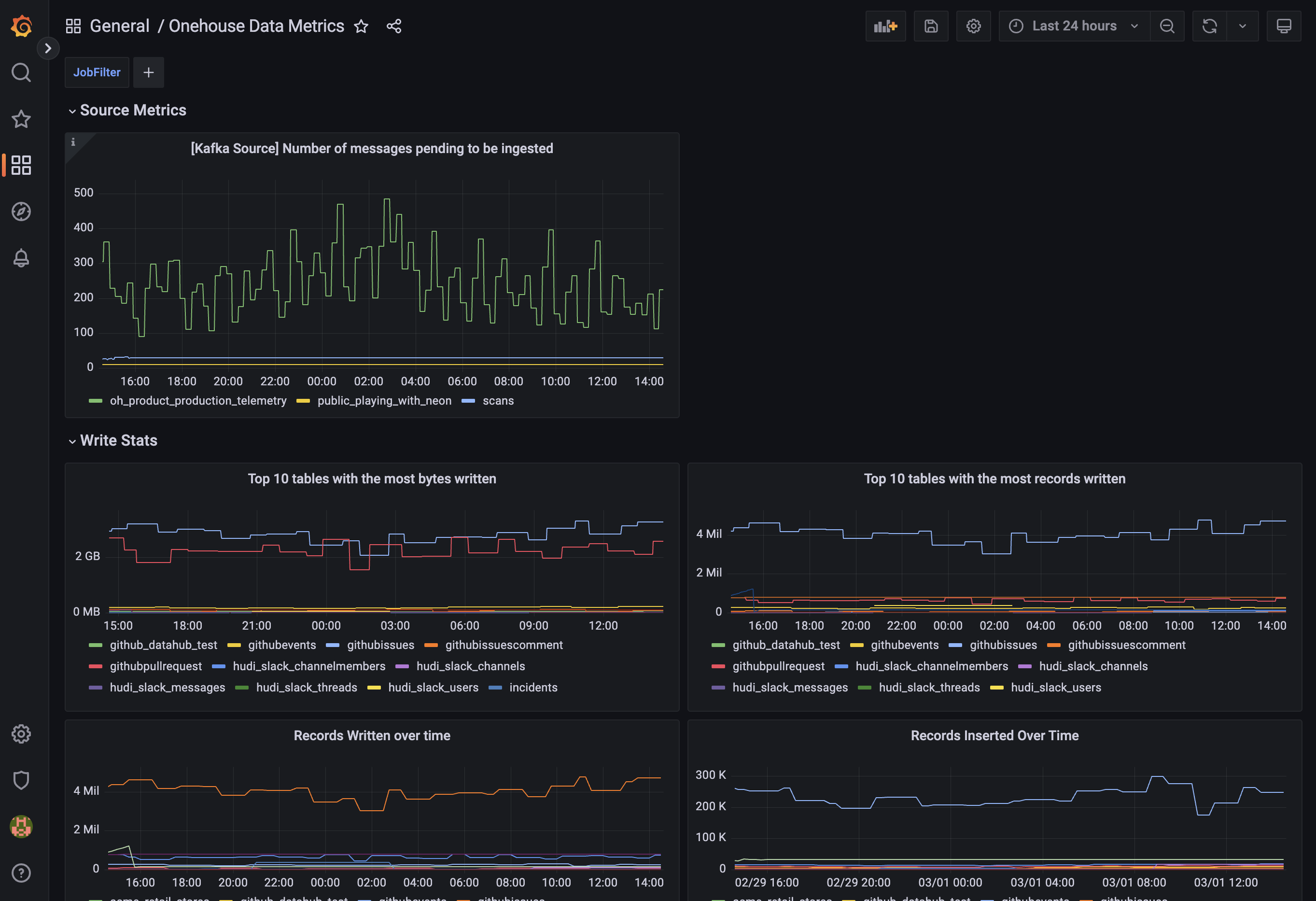
Write Stats
Monitor write operations across your Flows and Tables. Charts included:
- Tables with Most Bytes Written: Top tables by bytes written, including write amplification.
- Tables with Most Records Written: Tables with most records written, including record inserts, updates, and deletes.
- Total Bytes Written: Total bytes written, including write amplification.
- Records Written over Time: Records written, including inserts, updates, and deletes.
- Records Inserted over Time: Records written, filtered to inserts.
- Records Upserted over Time: Records written, filtered to upserts. Note that a single record may have multiple upserts.
- Records Deleted over Time: Records written, filtered to deletes.
Lag Monitoring
Monitor the lag of write operations. Charts included:
- Data Pending to be Ingested (from Kafka source): Volume of Kafka messages in the source topic that have NOT been ingested yet.
- Sync Duration vs. Configured Sync Frequency: Sync Duration refers to the full time for a sync to process all data remaining in the source (including reading, writing, and syncing data to the catalog). Sync Frequency is the minimum interval for the Flow to trigger each sync. If Sync Duration is greater then the Sync Frequency, the Flow may be delayed.
- Flows with Longest Sync Durations: Sync Duration refers to the full time for a sync to process all data remaining in the source (including reading, writing, and syncing data to the catalog). Filtered to the top 10 Flows by Sync Duration.
- Number of Consecutive Sync Lags: Describes how many syncs in a row the Sync Duration was greater than the configured Sync Frequency for a Flow.
- Absolute Time of the Last Sync: Sync Duration for the last Flow sync.
- Number of Sync Failures: Describes how many syncs failed for a Flow. Note that Flows will retry a sync upon failure, then will move to the Failed state after several failed attempts.
Table Services Monitoring
Monitor table service runs. Charts included:
- Compaction, Clustering, and Cleaning Duration for All Tables: Duration of each table's most recent run of the Compaction, Clustering, or Cleaning service.
- Compaction, Clustering, and Cleaning Duration for Top Tables: Duration of each table's most recent run of the Compaction, Clustering, or Cleaning service. Filtered to the top 10 tables by duration.
- Bytes Written by Compaction and Clustering Commits: Data volume written in each table's most recent run of the Compaction or Clustering service.
- Number of Partitions Touched by Compaction and Clustering Commits: Partitions with at least one write in each table's most recent run of the Compaction or Clustering service. Large numbers may indicate an inefficient partitioning scheme.
- Number of Files Deleted by Cleaning: Files deleted in each table's most recent run of the Cleaning service.
OCU Usage
This dashboard provides a breakdown of the OCU usage across all Flows and Table Services.
Charts included:
- OCU Usage Per Resource: Percentage of OCU used by each Flow and Table Service.
- If you have S3 or GCS sources, you will see a "metadata" job in the chart. Onehouse deploys one metadata job per bucket to monitor new files to be ingested.
- OCU Usage Per Operation Type: Aggregate OCU usage breakdown by table service type.