Table Types: Merge on Read and Copy on Write
Merge on Read (MoR) and Copy on Write (CoW) are the two table types available in Apache Hudi that determine how these data updates are managed.
We generally recommend using Merge on Read (the default in Onehouse) unless you have specific use cases requiring Copy on Write tables.
Merge on Read (MoR)
MoR tables are best served for efficient, low-latency writes.
When updates arrive, they are written immediately to small, row-based delta log files rather than forcing a rewrite of the large columnar base files. This avoids significant disk I/O, resulting in the lowest possible write amplification.
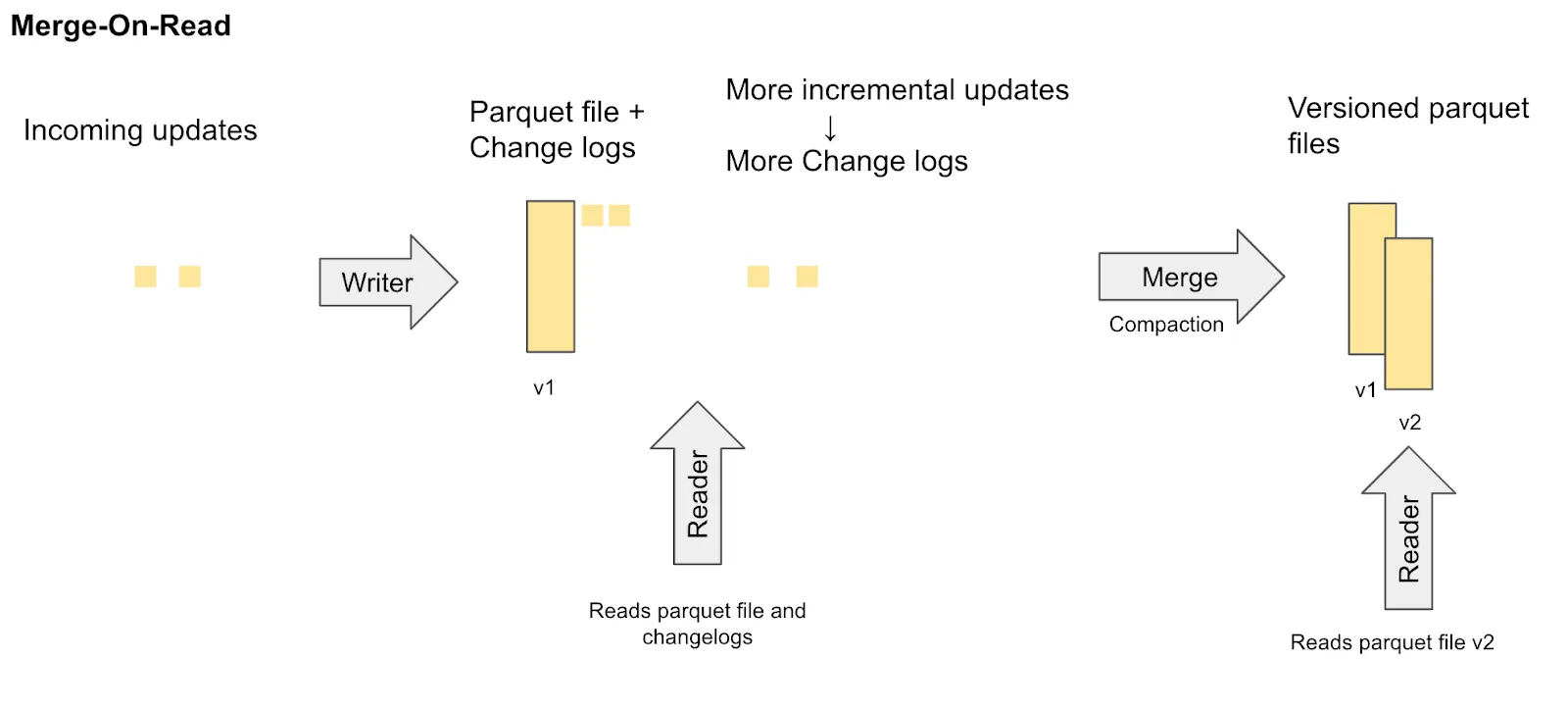
Merge on Read tables rely on a compaction service to merge the row-based log files into a columnar format for efficient reads.
Querying MoR tables
MoR tables expose two views for querying the table:
- The read-optimized (_ro) view exposes only the parquet files - ie. the updates that have been compacted. This enables fast queries, but does not show the updates in log files.
- The realtime (_rt) view shows the up-to-date state of the table by compacting log files on-the-fly. Queries can take longer, as log file compaction occurs at query-time.
For most scenarios where query latency is more important than minute-level freshness - the Read-optimized (_ro) view is a great option. For scenarios where you need realtime (_rt) views, it is recommended to run the compaction service frequently to ensure your desired data freshness. You can even run compaction on every commit to mimic CoW behavior (though this trades off on the write efficiency).
Copy on Write (CoW)
CoW tables are better served for simplicity and fast query performance when write costs and latency are less of a concern.
When updates arrive, the entire affected columnar base file (generally parquet) is rewritten to create a new, clean version of the file. In update-heavy scenarios, this may lead to a high write amplification, as every update mandates a costlier full file rewrite.
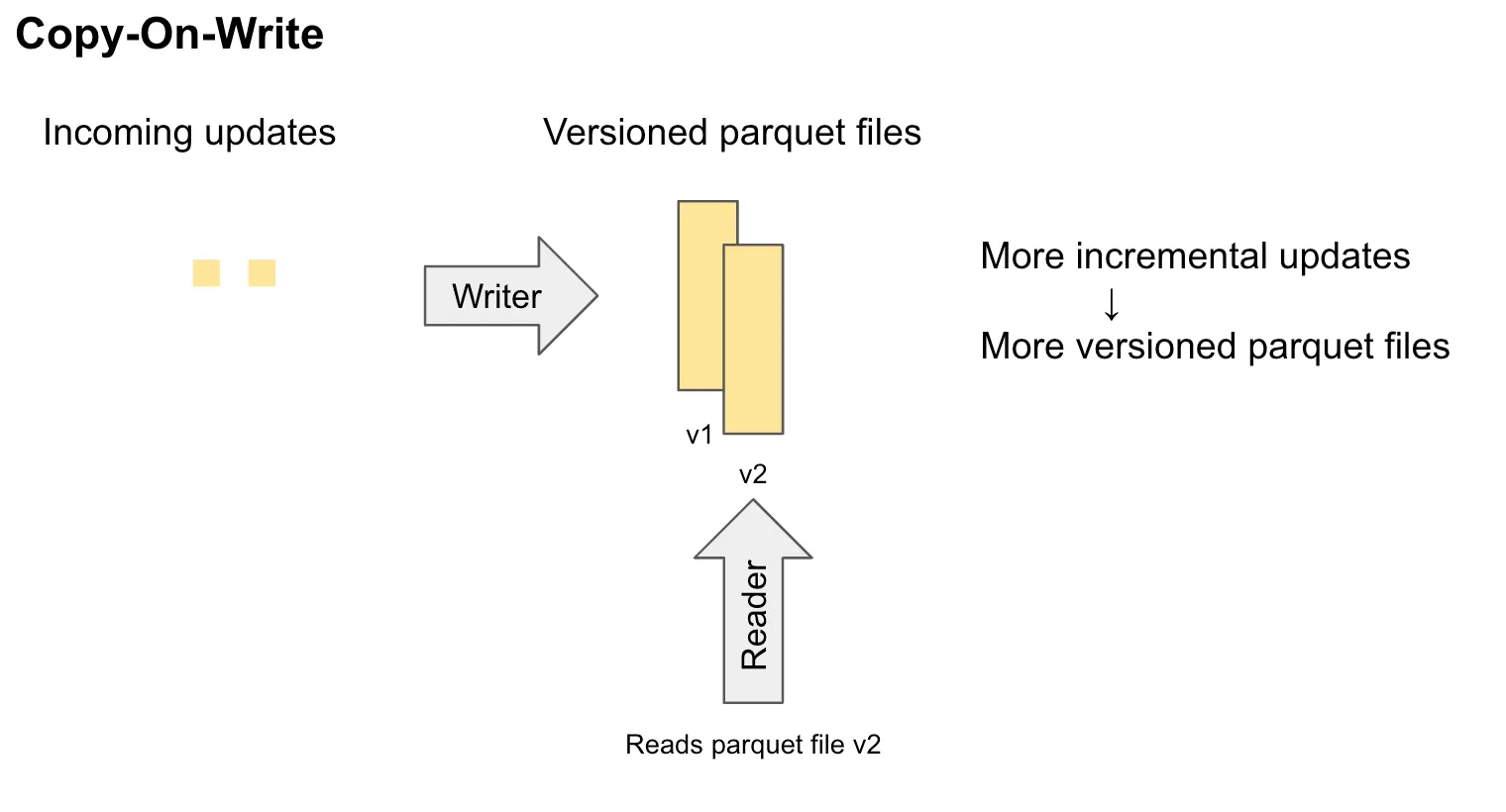
Querying CoW tables
Since the base files are always clean and fully merged, query engines can read them directly without the need for any merge operations/logic. CoW tables only expose a single view, which is effectively both realtime and read-optimized.
MoR vs CoW - Head-to-Head Comparison
| Feature | Merge on Read (MoR) | Copy on Write (CoW) |
|---|---|---|
| Table Type Config | MERGE_ON_READ (Default) | COPY_ON_WRITE |
| File Structure | Parquet Base Files + Log Files | Only Parquet Base Files |
| Best Use Case | Streaming, CDC, Heavy Updates | Batch, Read-Heavy |
| Write Mechanism | Inserts onto Base Files, Updates to Delta Log Files | Rewrites entire Base File |
| Write Performance | Faster, Lower Write Amplification | Slower, Higher Write Amplification |
| Read Performance | Fast after compaction or with read-optimized view; slower with realtime view when log files exist | Fast (reads clean files) |
| Query Views | Offers both Realtime (freshest data, slower queries if many log files exist) and Read Optimized (fastest query, compaction mitigates data freshness issues) views | Offers only a single view equivalent to Snapshot/Realtime |
Setting Default Table Types
By default, every new Flow on Onehouse provisions its destination table as Merge on Read (MoR). This standard setting is optimized for maximum efficiency on update-heavy workloads with more configurability at query time.
While every Flow on Onehouse would be created as MoR by default, users can set this option to Copy-on-Write for any new flow - as part of the “Table Type” configuration under Advanced Configuration of every flow configuration.
Project Admins can also toggle project level defaults for Table Types on the Project Settings page.
Read more about Table Types on Hudi: