Custom Transformations
Description
When creating a Onehouse Stream Capture, you have the option to configure transformations for your data pipeline. Onehouse provides a set of pre-installed low-code transformations for common operations.
If your use case is not met by these built-in transformations, you can leverage our Custom Transformations feature to extend the capabilities of our platform to tailor to your individual business requirements.
Introduction to Onehouse Custom Transformations
When Onehouse processes your data in a Stream Capture, it uses Apache Spark and Apache Hudi behind the scenes. The Onehouse transformation framework leverages the transformer capabilities available in open source Apache Hudi. To use custom transformations in Onehouse you will follow these 3 high level steps that are documented in more detail below:
- Prepare your custom transformation
- Upload a JAR file to Onehouse
- Add your custom transformation to a Stream Capture
How to prepare your custom transformation JAR File
Author the transformations
To author your custom transformation logic, you will start by extending the transformation class in Apache Hudi: https://github.com/apache/hudi/tree/master/hudi-utilities/src/main/java/org/apache/hudi/utilities/transform
- Create a java project with a maven like tool.
- Add hudi-utilities_2.12 as dependency to the project with provided scope and hudi version as 0.14.1, Also you are free to use spark packages for example
spark-sql_2.12but please mark the scope as provided. - Build the project with a command as per your choice of build tool, for example for maven it would look like
mvn clean package.
Example
Let's write a simple 'hello world' transformer that adds a new column (just for demo purpose) in your application.
You may need to add a dependency to hudi-utilities with provided scope so that you get access to the transformer
interface and also spark-sql_2.12 with provided scope as we are utilizing some spark functions.
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-utilities_2.12</artifactId>
<version>0.14.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.4.4</version>
<scope>provided</scope>
</dependency>
package org.apache.hudi.transformer
import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.utilities.transform.Transformer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.functions;
public class HellpWorldTransformer implements Transformer {
private static final Logger LOG = LogManager.getLogger(HellpWorldTransformer.class);
@Override
public Dataset<Row> apply(JavaSparkContext javaSparkContext, SparkSession sparkSession, Dataset<Row> dataset, TypedProperties typedProperties) {
LOG.info("Within hello world transformer");
return dataset.withColumn("new_col", functions.lit("abc"));
}
}
Compile the JAR file
Build the JAR using packaging options offered by standard build tool of choice. For example for maven it would be mvn clean package.
Best Practice Recommendations
We recommend you include only one class per JAR file as this may be easier for you to maintain and keep track of between your internal Devops system and what you upload to Onehouse.
Limitations
Environment Requirements: Use: spark 3.4.x, scala 2.12, and java 8.
Upload your custom transformation JAR File
When your JAR file is ready to upload to Onehouse you can navigate to Settings > Integrations. Click on Manage JARs:
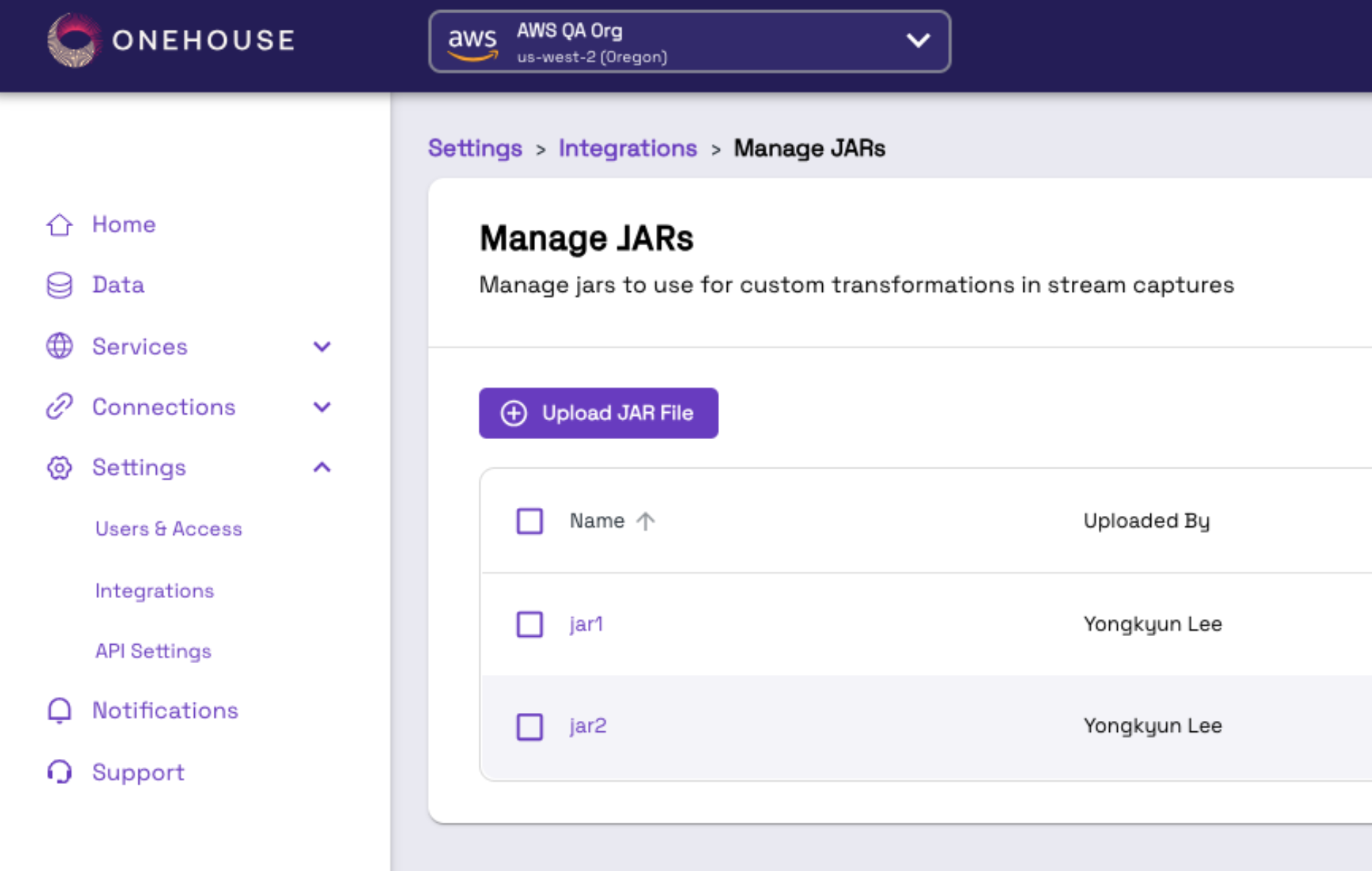
Here you will see the full collection of JAR Files that you upload. Click Upload JAR File:
Provide a unique name for your JAR file and then either upload from your local machine or specify an S3 path where the JAR file is located:
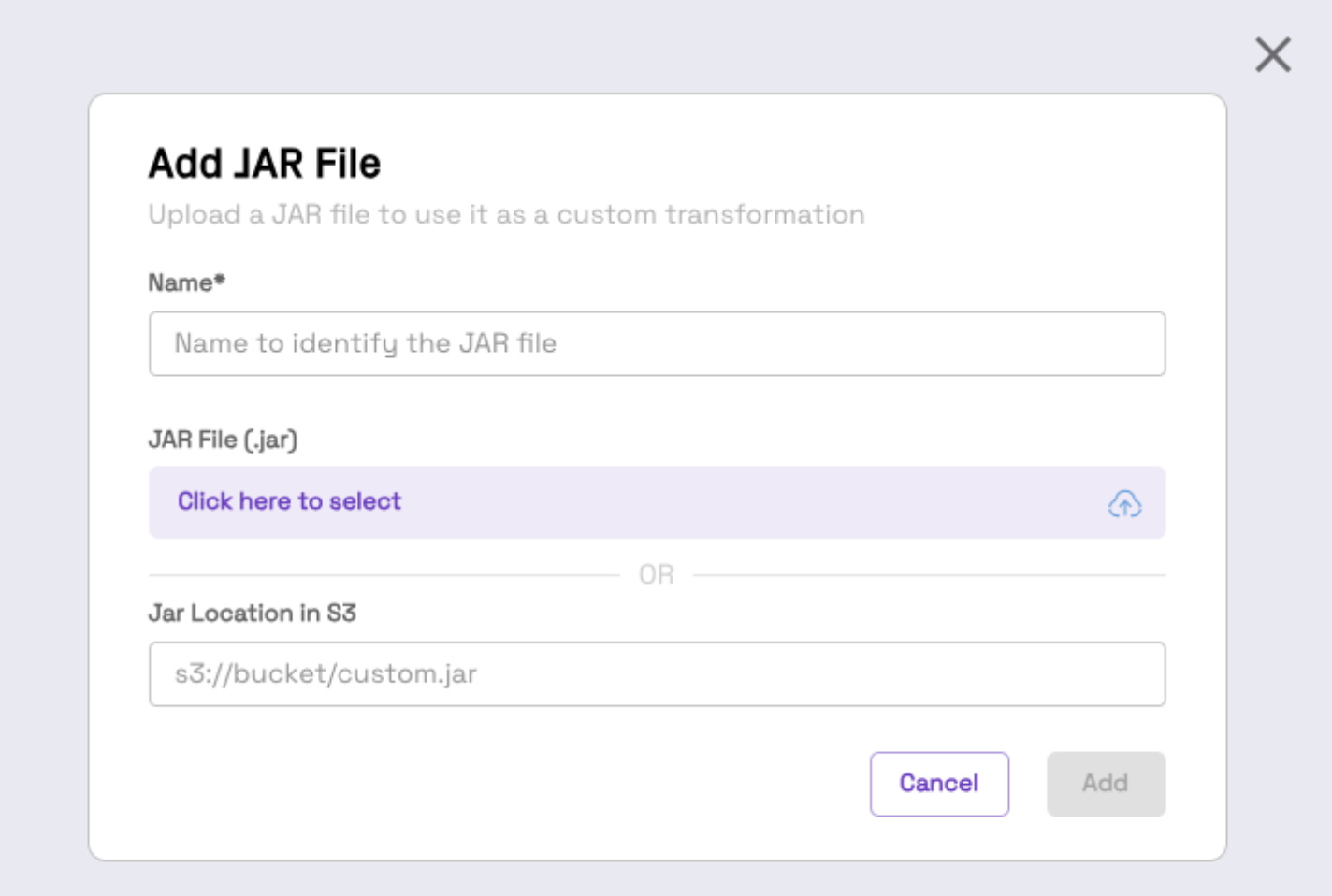
If you provide an S3 path make sure that it is a bucket that you granted Onehouse access to during onboarding: https://docs.onehouse.ai/docs/product/integrations/sources/aws-s3
Click Add JAR.
Common reasons for a JAR File to fail on upload:
- There is a class in this JAR which also exists in another JAR, you cannot have class name collisions
- If the JAR with same name exists and user isn’t using replace option.
- If we don’t have enough permissions to read from the source object storage path.
Add a custom transformation to a Stream Capture
Once your JAR file is uploaded you will be able to see all the class names or transformations exposed in the Stream Capture create/edit page when you select the transformations configuration drop down. In the screenshot below, the gear icon represents that it is a custom transformer.
![]()
Custom properties in your transform
When adding a custom transformation to your Stream Capture, you can optionally set custom key/value properties if your transformer expects them. Click the add new property button:
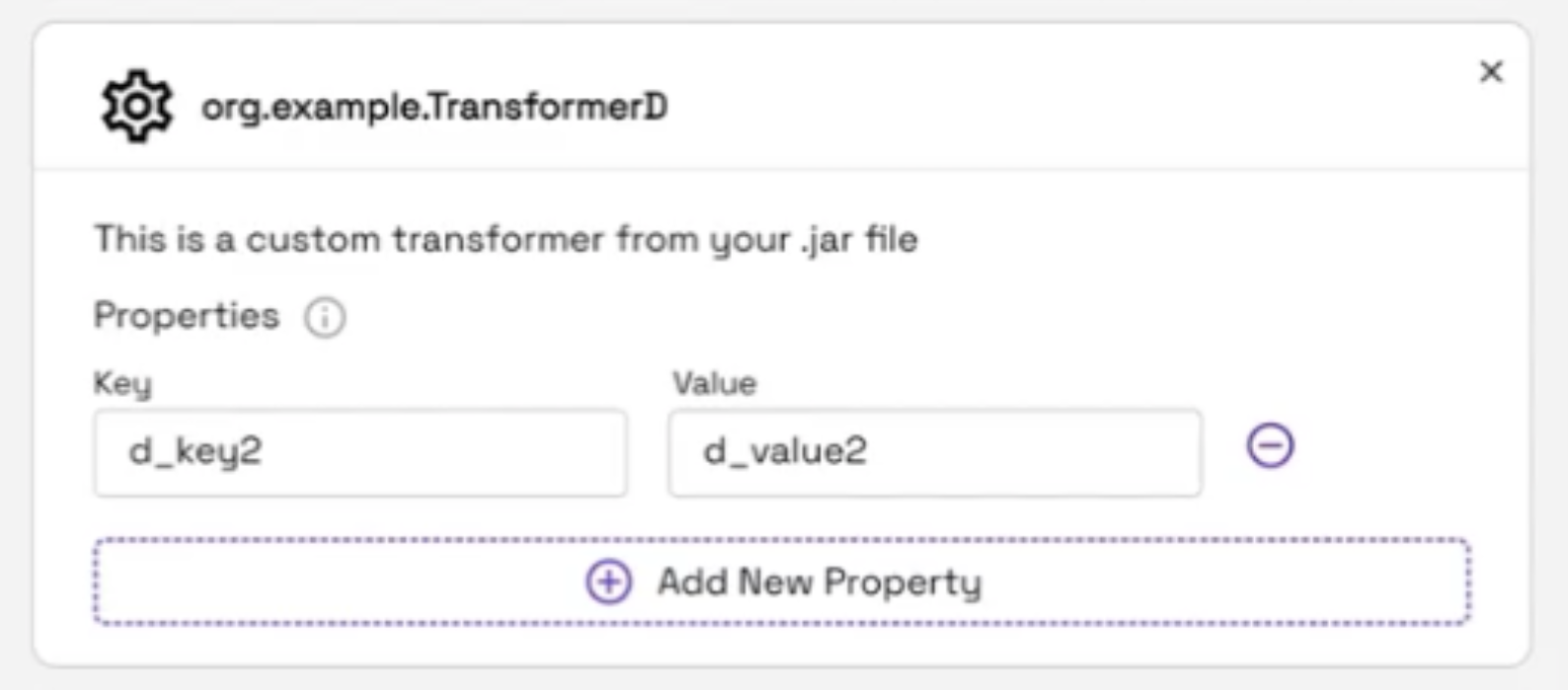
Enter the key name that your transformation expects and provide any custom value you would like to submit.
Update your custom transformations
If you need to change the logic in your custom transformations that are added to an already running Stream Capture you have two options.
- Create a new custom transformation and swap it in the Stream Capture settings.
- Replace your existing JAR file with the new logic and it will automatically deploy to existing Stream Captures that are using that transformation.
Caution:
- When adding and replacing JAR files, the Spark Jobs that Onehouse is operating will be restarted so that the latest files are picked up. All of your pipelines will briefly pause and resume. They will be resilient to failure and will only delay the processing by a few minutes.
- When you update the logic in an existing class and replace a JAR file, all Stream Captures that use this transformer will automatically be updated to the new logic. Please be certain you want to replace the logic in all places this transformation is used.
To replace a JAR file navigate to the actual file you would like to replace in the Manage JAR list:
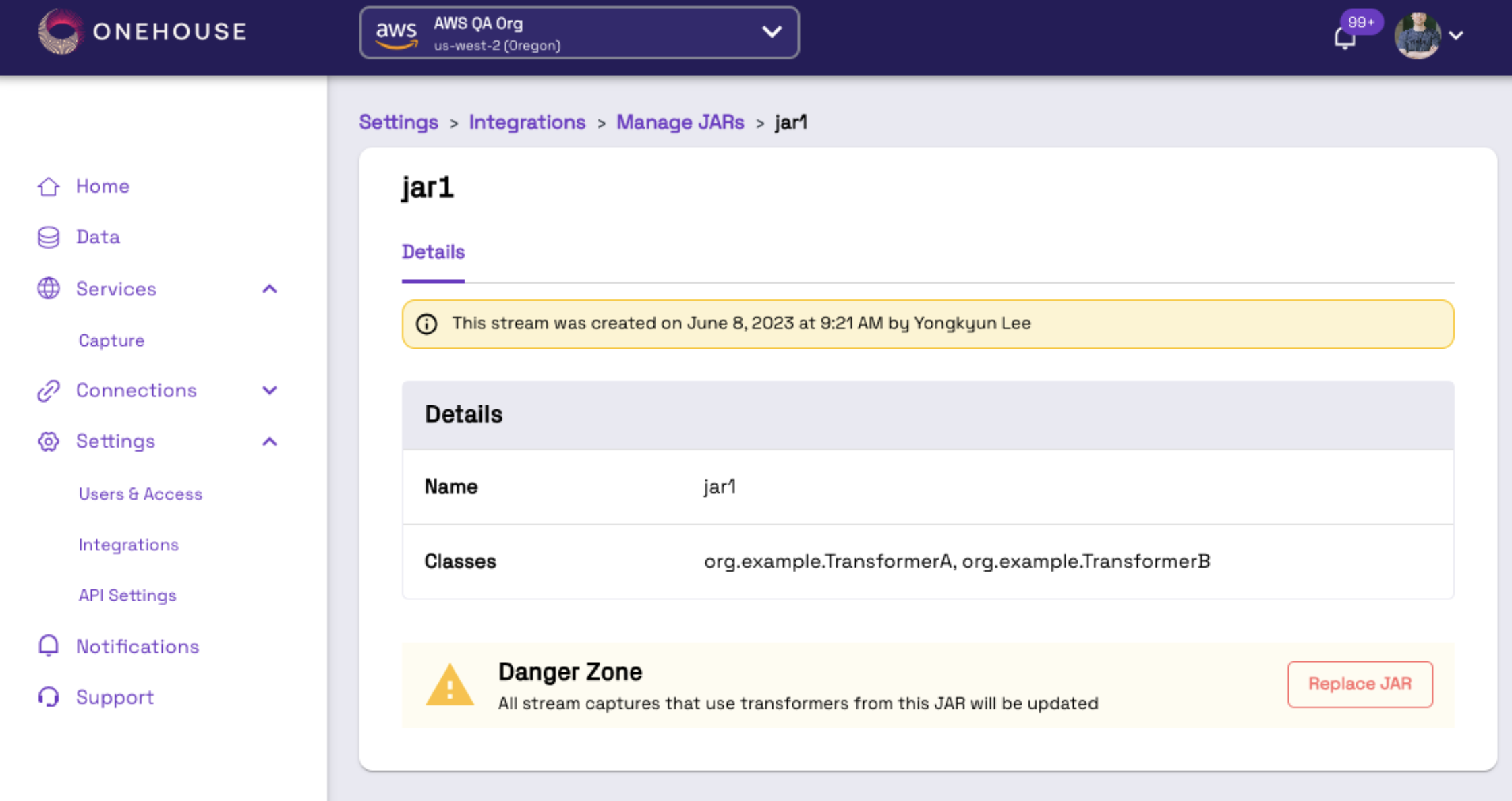
The replace JAR button is in the Danger Zone for the cautions called out above. Click Replace JAR and follow the same steps as Uploading a JAR.
Known Limitations and recommendations
- If you upload a JAR from local computer, the file size cannot exceed 4MB.
- You can remove transformations from Stream Captures, but you cannot delete a JAR altogether in the UI today. Contact support if you need to delete a JAR file.
- Ensure sufficient unit testing/ integration tests are done prior to deployment.
- Ensure deployment of transformations are done during non-business hours.
- Limit implementation to data and schema manipulations, row or column filtering and data cleansing.
- Avoid running aggregations and joins of datasets across multiple tables. Doing so could impact the performance of the pipeline in terms of latency. It could potentially stall pipelines due to OOMs. Onehouse provisions the data clusters according to the volume of the data from the primary source. Please consult Onehouse support if you have such a use case.
- If you have multiple transformations or functions, it is recommended to split across multiple transformer classes.
- Avoid including third party dependencies, and consult with Onehouse support team if its essential to use a third party dependency (such as libraries, JARs etc.)